
8月笔记
8.1 Hive压缩和存储 以及优化
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 | 第九章 压缩和存储 |
3.所学内容概述
hadoop压缩配置
压缩参数配置
开启Map输出阶段压缩 利用MR
企业调优
4.根据概述分章节描述
个人理解
压缩和解压和我们平常window使用的差不多,虽然是在hive中的压缩和解压 但是底层还是利用hadoop中的MR,所以压缩编码也是MR所支持的。
有哪些我截图出来
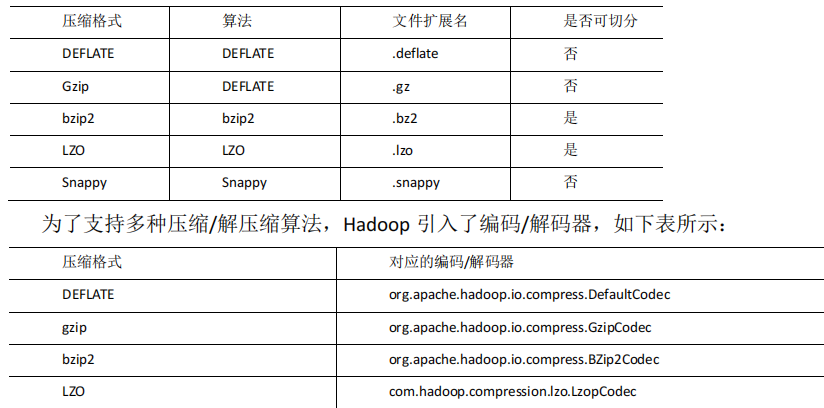
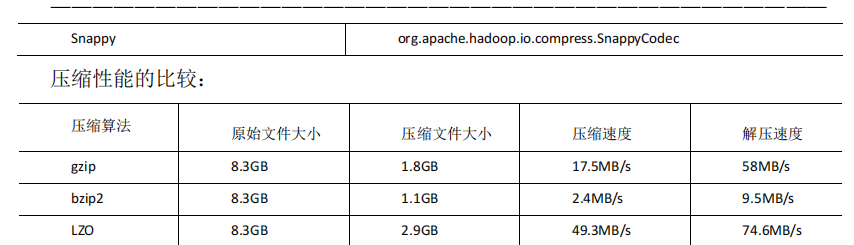
根据性能比较,可以看出 LZO的性能远远领先于其他两个
在实际的项目开发当中,hive 表的数据存储格式一般选择:orc 或 parquet。压缩方式一般选择 snappy,lzo。
开启Map输出阶段压缩
因为map输出阶段压缩中job,数据传输量很大,所以我们根据效率需要适量减少,在job中工作的是map和reduce task间数据传输。利用hive代码开启
分4步 最后一步是查询
1 | --1.开启hive中间传输数据压缩功能 |
开启Reduce输出阶段压缩
如果hive已经把数据导入的表中没这个时候怎么压缩,就需要用Reduce
hive.exec.compress.output在hive中 默认设置为false 意思就是输出是纯文本文件
设置为true 就是压缩文件
也是四条命令 最后一条查询 可以查询输出文件
1 | --(1)开启 hive 最终输出数据压缩功能 |
企业级调优
在尚硅谷给的文档中有,比较多,而且目前对自己学习用处不大。就不计入笔记了。
5.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的学习任务不是很重,基本算是hive的完结了。 压缩和存储,跟着文档试着整了一下,花费的时间比较多,三个来小时,然后静下心去看了优化的文档,看完,认为对以后hive操作,应该用处挺大的,主要就是提高效率问题,但是有一些麻烦,而且比赛也不会设置这些参数,就先不去纠结了,今天倒是没有什么难点,明天试着去做hive题库了。
8.2 Hive复习 sqoop完结
1-头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 | P101_尚硅谷_Sqoop_课程介绍 |
3-所学内容概述
安装sqoop
导入的几种方式
导出数据
脚本调用
根据概述分章节描述
什么是Sqoop
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库mysql间进行数据的传递,可以将一个关系型数据库Mysql中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
我理解就是导入导出数据库方便
Sqoop安装
1 | 下载并解压 |
导入数据
导入数据就是从非大数据集群 也激素RDBMS 向大数据集群 HDFS Hive Hbase 这些 传输数据 俗称导入
从RDBMS到HDFS
1.全部导入
1 | bin/sqoop import \ |
2.查询导入
1 | bin/sqoop import \ |
如果query后使用的是双引号,则$CONDITIONS前必须加转移符,防止shell识别为自己的变量。
3.导入指定列
1 | bin/sqoop import \ |
columns中如果涉及到多列,用逗号分隔,分隔时不要添加空格
4.使用sqoop关键字筛选查询导入数据
可以自定义筛选或者对数据进行处理
1 | bin/sqoop import \ |
RDBMS到Hive
1 | bin/sqoop import \ |
该过程分为两步,第一步将数据导入到HDFS,第二步将导入到HDFS的数据迁移到Hive仓库,第一步默认的临时目录是/user/root/表名
RDBMS到Hbase
1 | bin/sqoop import \ |
手动创建HBase表
1 | hbase> create 'hbase_company,'info' |
HBase查看表scan命令
1 | scan 'hbase_company' |
导出数据
就和导入反过来了 从大数据集群到非大数据集群传输数据 叫做导出 export 关键字
1 | bin/sqoop export \ |
脚本打包
使用opt格式的文件打包sqoop命令 我的理解就是把命令封装 然后调用
1 | vi opt/job_HDFS2RDBMS.opt |
扩展学习部分
Hive练习
1 | --查询平均成绩大于等于60分的同学 |
总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
上午都在安装环境,因为sqoop之前要安装zook和hbase,去看了尚硅谷之前的安装视频,还是挺顺利的,一上午就搞好了,但是在sqoop,从HDFS导出数据到Hive的练习的时候,出现了问题,就是运行过程,到一半卡住不动了。去搜解决问题说是虚拟机CPU分配问题,以后是在服务器上使用的,就没去管了,知道怎么导出就好了。今天的学习状态很不错的,都很顺利,没有之前安装Hive的那种烦躁感,sqoop的使用也比较简单,重点在导入数据,也是蛮容易的,全都掌握了。
8.4-8.7 省赛题目分析
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.所学内容概述
大数据省赛和国赛spark代码分析
3.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
这几天都是看比赛流程,读懂任务书什么的,还有李昊清洗的代码和sql语句,先看大致的流程,每个案例都怎么弄。每一个函数的作用什么的 , 在刚看到这些代码都懵逼了,一些关键字都不知道是干嘛用的。不知道的就一个一个去搜,是什么作用,反正去搞懂大致先了,难懂的点在spark的自定义的函数,读取文件什么的,这些弄了很久才搞明白,这两天去问了李昊很多问题,sql啊spark什么的。
8.8-8.9 SparkSQL深度集成
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
3.所学内容概述
SparkSQL用IDEA操作Hive的进阶操作
4.根据概述分章节描述
封装SparkSQL连Hive方法
因为每次写SparkSQL代码的时候都需要,写一大串连接Hive的代码,所以自己为了省时间将代码封装到一个工具类了,写SparkSQL代码前调用一下就好了
1 | package com.atguigu.bigdata.sparksql |
具体使用

使用insertInto向hive表中写入数据
1 | package com.atguigu.bigdata.sparksql |
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
这两天大部分时间都在调配置,代码是没有问题的,但是IDEA一直连不上虚拟机中的hive,晚上才发现是版本问题,第二天就去重装了三台,linux中spark也因为版本问题,导致要全部重装,因为自己把Hive的计算模块从MR换成了Spark,换Linux的spark换了一上午的时间,下午才去在IDEA学SparkSQL操作hive,内容倒是不难,基本就是把hive中的代码放到SparkSQL的语句中去,sql(“show tables”),这种类似,唯一的难点就是IDEA连上hive了。
8.10 Hive实战之影音数据分析
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 | P119119-尚硅谷-Hive-案例实操 需求一 |
3.所学内容概述
今日学习部分
SparkSQL商品
Hive影音
4.根据概述分章节描述
Spark项目实战
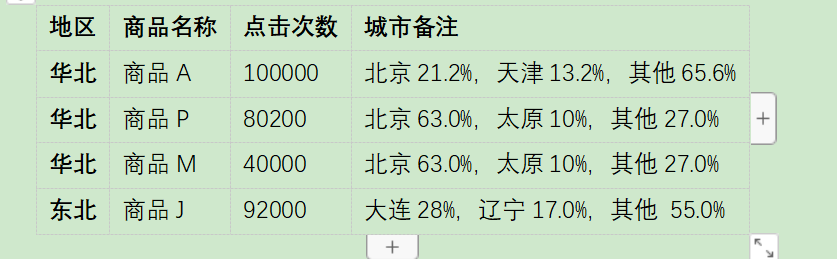
各区域热门商品Top3
效果图
注意是要自定义udaf函数 比较难 不太好掌握 所以是跟着老师敲的
1 | package com.atguigu.bigdata.sparksql |
Hive影音
数据清洗
写好ETL代码
利用maven将运行的java代码打包
1 | bin/yarn jar /opt/module/software/subject/sparksql-1.0-SNAPSHOT.jar com.atguigu.bigdata.sparksql.VideoETLRunner --运行代码包名 |
创建表导入数据
做题
答案和步骤都在IDEA里面 包在 bigdata package com.atguigu.bigdata.sparksql.day7SubjectTest
—统计视频观看数Top10
—统计视频类别热度Top10
—统计视频观看数Top20所属类别
—统计视频观看数Top50所关联视频的所属类别Rank
—统计每个类别中的视频热度Top10
—统计每个类别中视频流量Top10
—统计上传视频最多的用户Top10以及他们上传的视频
—统计每个类别视频观看数Top10
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天学习的任务不是很重,实战性的,上午把上次的SparkSQL操作的商品表的查询筛选复习了一下,把Hive实战的电影表和用户表建了一下,下午去敲代码,还是很简单,轻松的。因为之前反复琢磨了50题的hive,做了四五天呢,所以看清楚表的结构和要求,敲出来不难。
8.11 SparkSQL向hive表写入数据
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 | 1-2-2 使用saveAsTable向Hive表中写入数据-1 |
3.所学内容概述
SparkSQL向Hive表写入数据的几种方式
4.根据概述分章节描述
使用saveAsTabel向Hive表中写入数据
自己大部分对代码的解释都 在 注解那边
1 | package com.atguigu.bigdata.sparksql |
将代码打包 放linux执行 需要修改一些配置 以及在pom.xml文件中 增加
1 | package com.atguigu.bigdata.sparksql |
利用SparkSQL向hive表写入数据 (推荐)
1 | package com.atguigu.bigdata.sparksql |
5. BUG点
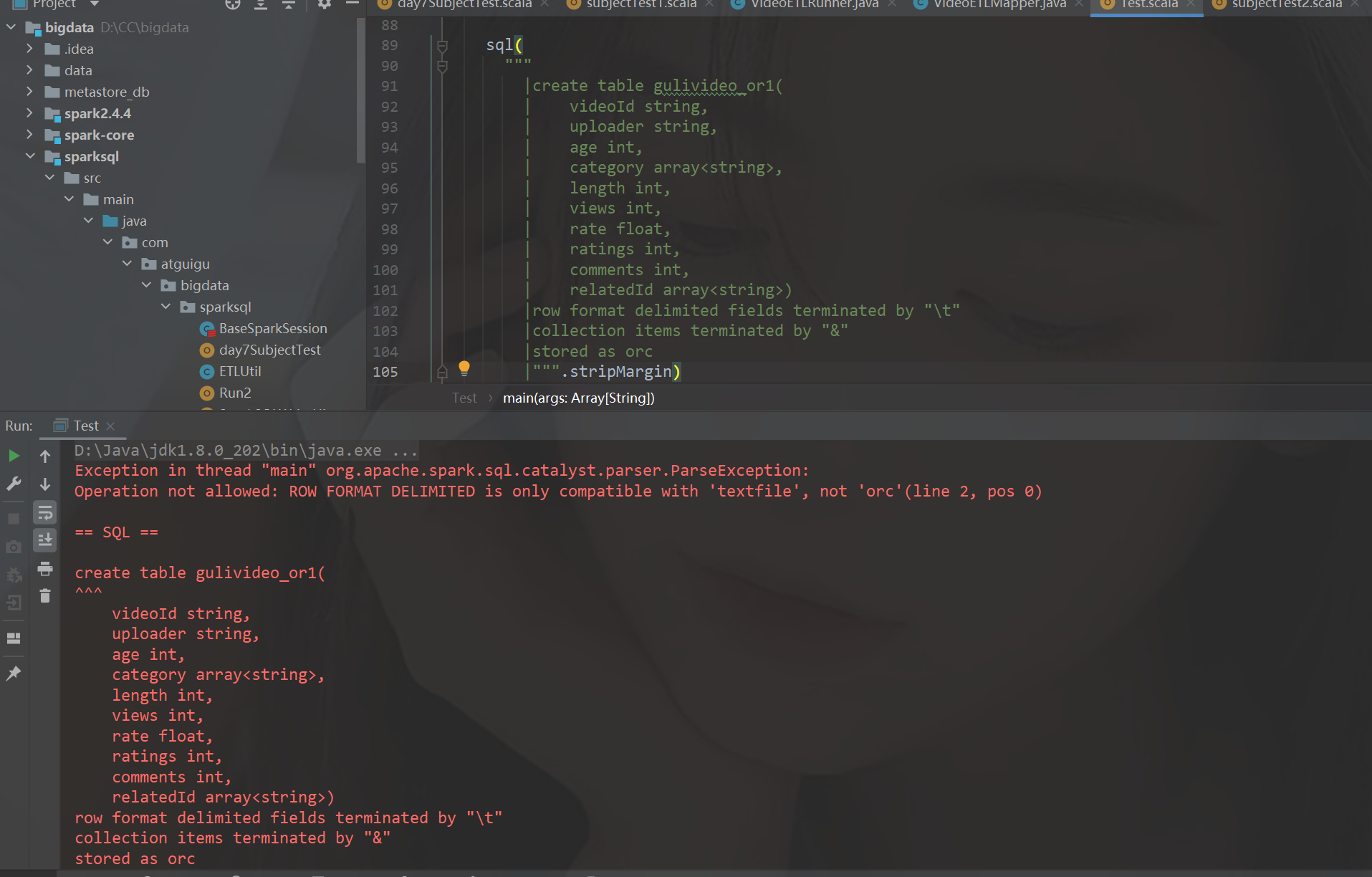
难点(关键代码或关键配置,BUG截图+解决方案)
看报错点是最后一行的stored as orc 翻译说是sql不能用orc文件 CSDN搜索
官方建议在hive中建表 在SparkSQL中使用,因为在spaek只能默认textfile 想要指定需要使用using
有效指定 create tablet1(id int) using hive options(fileformat’textfile’)
fileformat支持的六种参数 sequencefile rcfile orc parquet textfile avro
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天学习了Spark的进阶操作吧,向hive表中添加处理数据,这样的添加方式。可以在将数据过滤以后, 把新过滤好的数据,建立成新的表。 老师讲课说saveAtTable这种方法太麻烦了,平常还是使用SparkSQL比较多。但是看大三的省赛大数据数据清洗的代码是有用到saveAtTable的.
8.12 with … as Hive sql理解
1.头:日期、所学内容出处
3.所学内容概述
with … as
参考博客如上
with as 也叫做子查询部分,首先定义一个sql片段,该sql片段会被整个sql语句所用到,为了让sql语句的可读性更高些,作为提供数据的部分,也常常用在union等集合操作中。
with as就类似于一个视图或临时表,可以用来存储一部分的sql语句作为别名,不同的是with as 属于一次性的,而且必须要和其他sql一起使用才可以!
其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,这可以大大的简化SQL;更重要的是:一次分析,多次使用,这也是为什么会提供性能的地方,达到了“少读”的目标。
简单使用 语法
1 | WITH t1 AS ( |
注意点
1 | 1--with子句必须在引用的select语句之前定义,同级with关键字只能使用一次,多个只能用逗号分割;最后一个with 子句与下面的查询之间不能有逗号,只通过右括号分割,with 子句的查询必须用括号括起来. |
自己使用分析
1 | /*不使用with as*/ |
以上案例可见,with 对Hive可读性的提升是显而易见的。
其实一些时候是可以用with as 代替 join on 的但是我觉得join on更方便而且代码量比较少 所以像表格嵌套去查的时候,我才会去使用with as来提高可读性
Hive查询结构完整
1 | select distinct.... |
hive执行顺序
1 | 1. 先执行 from 子句 |
注意:列别名和表别名尽量正确使用,在hive中,非常严格,有的时候必须加别名。
1 | 1. hql什么时候不会被翻译成mr程序 |
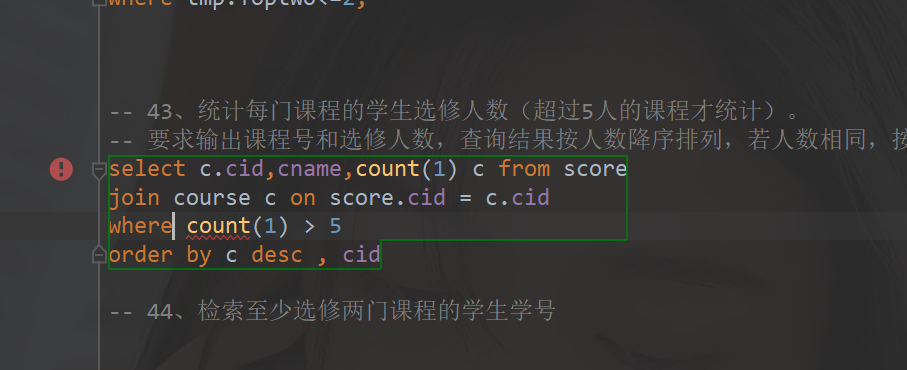
5. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
当我筛选count 取大于5的时候,报错了。后面注意到 ,count是聚合函数 需要分组才能使用。忘记加了group by 分组
总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天上午在看省赛数据清洗中sparksql那边的代码答案,学长写的,发现比较常用的with as这部分视频没讲,能很好的增强可读性,就去CSDN去搜了一下,sql下面还有read读数据的代码。总之就是代码看不懂的地方就一个一个去搜过来,搞懂作用,不行就问学长,下午又去做了几道hive的案例,多用了with as 原本 join 里面()t1这样的方式,查询嵌套真的不太看得懂,用了with as 自己写的sql语句,思路也清晰不少,别名出现的几次BUG也去看了一下,以后要多加注意。
8.13-8.17 hive 50题
1.头:日期、所学内容出处
2.所学内容概述
hive 50题自写 改进 用with as
3.根据概述分章节描述
因为之前hive刚看完的时候,直接去看省赛题目,李昊省赛的spark代码只能看个七八十,自己写估计是不大写的出来,问学长说sql语句比较重要,csdn搜hive sql 练习题 很多都是50道经典题,但是都是用很麻烦的方法,看学长的with as 句,就直接打算自己用with as 自己写。
sql 语句 如下
像25题有很多种解法,我自己就列出来了3种。
1 | -- 4.查询平均成绩小于60分的同学的学生编号和学生 |
4.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
这几天任务量也不算大,其实超出了自己的时间,本来打算3天写完,然后1天去总结的。但是发现hive这些语句和B站讲的都不太一样,老师所讲的自己没有去实操过,老师给的题目都是很简单的。像这种稍微有点难度的,需要用大量的join 和 over() 这两个比较难的点,自己去找了很多文档,再看了几遍,觉得差不多了才去做题目。前面第一题就做了三题,到后面上手了一天能做15 道,最后一天17号早上写完了,下午又把语句一个一个运行,去分析每一个关键字的作用,当时是怎么想的,写出来的,模糊的,就再写一遍。
8.18-8.25 hive提高题 15
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.根据概述分章节描述
ti1
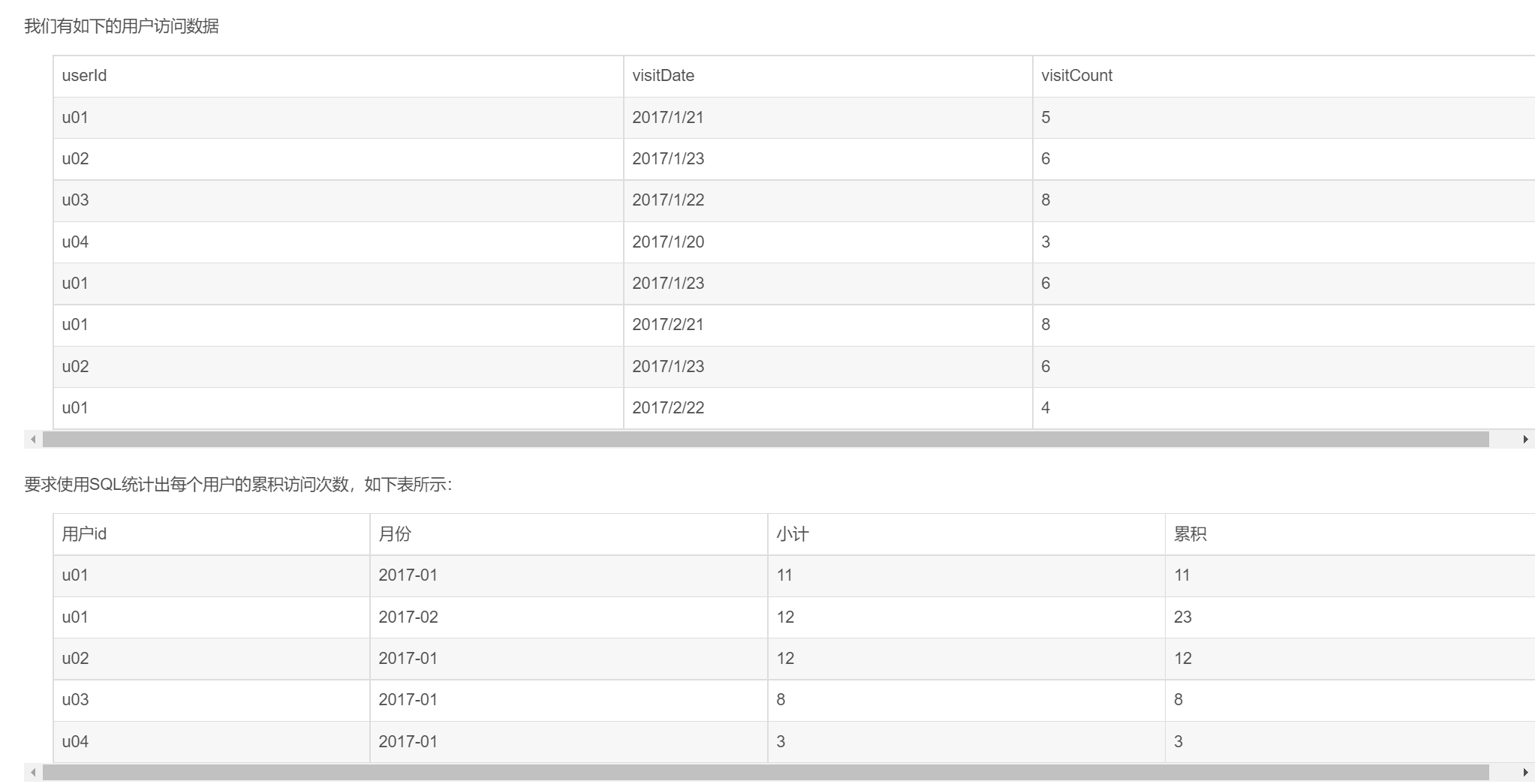
建表语句和SparkSQL代码
后面虚拟机打开,再开IDEA有点吃不消了,hive sql语句就放虚拟机里面了。
1 | package com.atguigu.bigdata.SparksqlTest15 |
1 | package com.atguigu.bigdata.SparksqlTest15 |
3. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
SparkSQL添加数据BUG
刚开始用sparkSQL向action表添加数据报错, 就直接去hive里面直接输入语句了
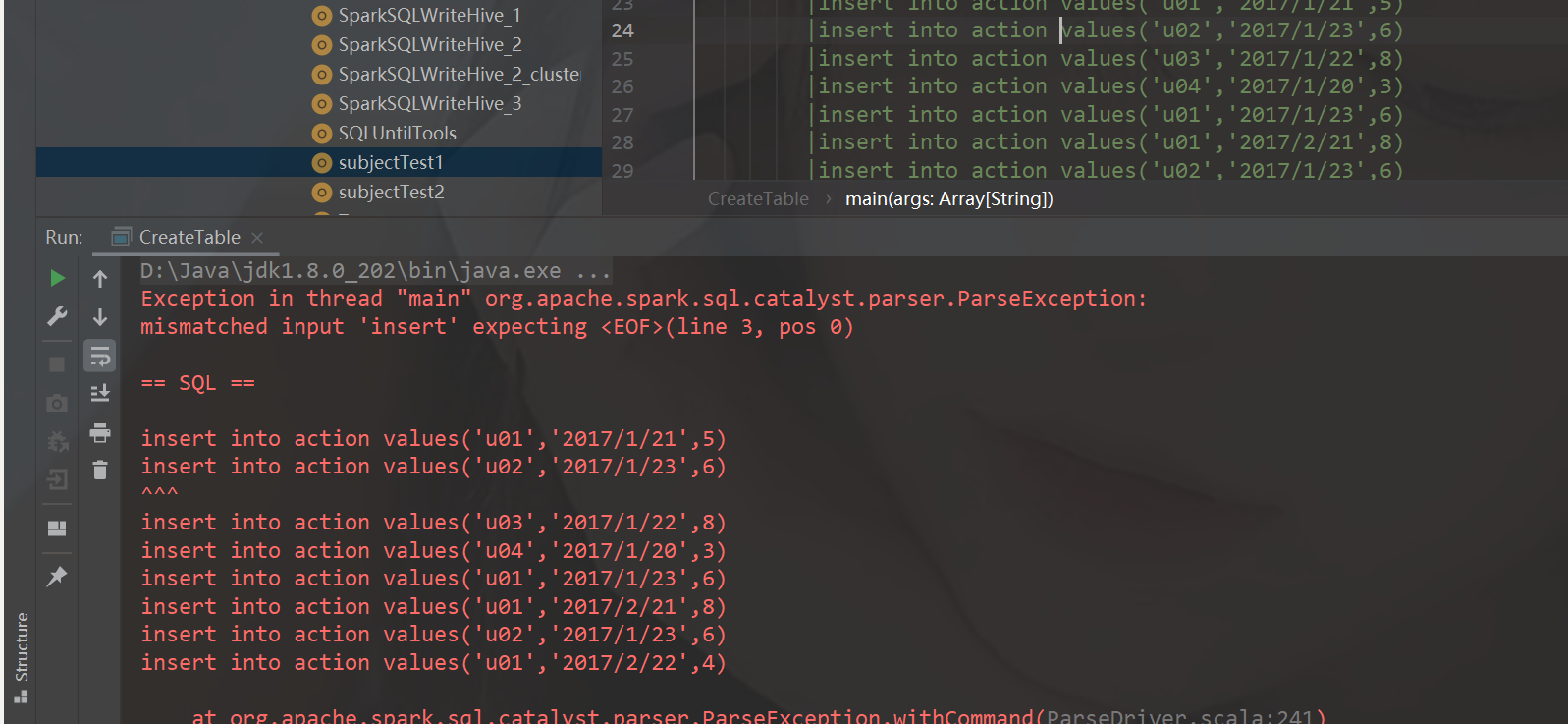
虚拟机Linux中Hive启动直接添加

成功
4.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
因为自己的任务主要是对数据的处理,也就是sql语句用的比较多,刚好CSDN看到hive提高题,点进去看,感觉还不错,数据也蛮经典的,就想着剩下来的时间刷省赛题之前,刷一下hive sql语句,能节省一点做题时间。这星期都在刷hive的题目,难度还是很大我觉得,前面几天基本一天一道,后面差不多一天两三题,去做完,自己敲完,和答案对一对,看看结果有什么不一样的地方。用spark添加数据这一块会报错,就直接把语句放到文件中,传到虚拟机里面,直接用hive执行,把数据添加好就行了。
8.26-8.27 sqoop增量导入
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 | 01--Apache Sqoop--软件介绍 |
4.根据概述分章节描述
在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据每次都全部导入到 hive 或者 hdfs 当中去,这样会造成数据重复的问题。因此一般都是选用一些字段进行增量的导入, sqoop 支持增量的导入据。
1 | 大白话讲 就是数据随着增加的,导入 |
1 | --incremental append \ |
Append模式导入
1 | bin/sqoop import \ |
导入过后hdfs会多出一个文件 这个文件就是增量以后的数据 也就是ID 1205后面的数据 不包括1205
lastmodified模式导入、
1 | bin/sqoop import \ |
导入也会有一个文件
check-column列的数据需要是时间戳
last-value的值 增量导入以后 是时间后面的值 包括该时间
lastmodified 模式去处理增量时,会将大于等于 lastvalue 值的数据当做增量插入。
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
因为自己在看sqoop的那个视频很短,就两个小时,没有讲过增量导入这一章节,但是省赛任务书是第一点是数据抽取,而且是要求使用sqoop进行抽取,因为要抽8个表格,前面6个都是比较普通的全量抽取,之前自己学的也能做出来,但是到增量导入的时候, 我用sqoop就不知道怎么弄了,问李昊,他们比赛是给后面可视化的,所以没学sqoop,自己整也整不出来,任务书描述的还模糊,两天也没整出来。
8.28-8.31spark离线数据抽取
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.所学内容概述
IDEA中spark 代码 package打包
sparkSQL jar在linux执行
1 | spark-submit --master spark://192.168.23.89:7077 --executor-memory 2g --total-executor-cores 10 --driver-memory 4G --class com.atguigu.bigdata.Test.subjectTwoData --name subjectTwoData /opt/XXXX.jar |
打包过程
要加Maven插件
1 |
|
数据抽取的代码
省赛任务书模块D
spark增量 只用sql 这种where 就比sqoop 我觉得方便很多而且容易理解
1 | package BIGDATA |
3.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
前段时间因为sqoop增量自己整不来,然后李昊让我基本的sqoop学会就好了,练习题目就用spark,而且省赛说是不考sqoop的,所以我就直接用sparksql连hive,抽取数据了,就是直接用hive 查询导入到MySQL 或者 从MySQL到hive hive到hive都是可以的,动态分区也很方便,都会默认分区。这几天sparksql使用的比较多,也出现了很多大大小小的问题吧,麻烦的点在打包放linux,里面之前因为没加Maven插件,导致报错了,重新打包还是会报错,代码并没有更新。





