objectdataMath{ defmain(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder().master("local[*]").appName("subject1Extract") .enableHiveSupport() .config("hive.exec.dynamic.partition", "true") .config("hive.exec.dynamic.partition.mode", "nonstrict") .config("spark.sql.parquet.writeLegacyFormat", "true") .getOrCreate() import spark.sql //TODO T1 sql( s""" |with t1 as ( |select |province_id,final_total_amount, |date_format(operate_time,'yyyy') as year, |date_format(operate_time,'MM') as month |from dwd.fact_order_info |),t2 as ( |select |province_id as provinceid,sum(final_total_amount) as totalconsumption, |count(1) as totalorder, |year,month |from t1 |group by province_id,year,month) |select |t2.provinceid, |bp.name as provincename, |br.id as regionid, |br.region_name as regionname, |totalconsumption, |totalorder, |t2.year, |t2.month |from t2 |left join dwd.dim_province bp on t2.provinceid = bp.id |left join dwd.dim_region br on br.id = bp.region_id |""".stripMargin).write.mode("overwrite") .saveAsTable("dws.provinceeverymonth") //TODO T2 sql( """ |select |province_id as provinceid, |dp.name as provincename, |avg(final_total_amount) as provinceavgconsumption |from dwd.fact_order_info foi |left join dwd.dim_province dp on dp.id = foi.province_id |group by province_id,dp.name |""".stripMargin).createOrReplaceTempView("everyProvince") val d: java.math.BigDecimal = sql( """ |select avg(provinceavgconsumption) |from |everyProvince |""".stripMargin).first().getDecimal(0) sql( s""" |with t1 as ( |select |provinceid, |provincename, |provinceavgconsumption, |$d as allprovinceavgconsumption |from everyProvince) |select t1.*, |(case | when t1.provinceavgconsumption > t1.allprovinceavgconsumption then '高' | when t1.provinceavgconsumption = t1.allprovinceavgconsumption then '相同' | when t1.provinceavgconsumption < t1.allprovinceavgconsumption then '低' | end) as comparison |from t1 |""".stripMargin).write.mode("overwrite").saveAsTable("dws.provinceavgcmp")
//TODO T3 sql( s""" |with t1 as ( |select |user_id as userid, |cast(date_format(operate_time,'yyyyMMdd') as int) as day, |final_total_amount as consumption |from |dwd.fact_order_info), t2 as ( |select userid,day,sum(consumption) as totalconsumption,count(1) as totalorder |from t1 |group by userid,day |) |select |a.userid, |dui.name, |concat(a.day,'_',b.day) as day, |a.totalconsumption+b.totalconsumption as totalconsumption, |a.totalorder+b.totalorder as totalorder |from |t2 a |left join dwd.dim_user_info dui on dui.id = a.userid |left join t2 b on a.userid = b.userid |where |a.day + 1=b.day |and |a.totalconsumption<b.totalconsumption |""".stripMargin).write.mode("overwrite") .saveAsTable("dws.usercontinueorder")
sql( """ |with t1 as ( |select |user_id as userid, |cast(date_format(operate_time,'yyyyMMdd') as int) as day, |final_total_amount as consumption |from |dwd.fact_order_info) |select userid,day,sum(consumption) as totalconsumption,count(1) as totalorder |from t1 |group by userid,day |""".stripMargin) spark.stop() } }
objectdataMath{ defmain(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder().master("local[*]").appName("t3") .enableHiveSupport() .config("hive.exec.dynamic.partition", "true") .config("hive.exec.dynamic.partition.mode", "nonstrict") .config("spark.sql.parquet.writeLegacyFormat", "true") .getOrCreate() import spark.sql val t1: DataFrame = sql( """ |with t1 as ( |select |province_id, |final_total_amount, |substring(etl_date,1,4) as year, |substring(etl_date,5,2) as month |from dwd.fact_order_info foi), t2 as ( |select |province_id, |sum(final_total_amount) as total_amount, |count(1) as total_count, |year, |month |from t1 |group by province_id,year,month) |select |province_id, |dp.name as province_name, |dr.id as region_id, |dr.region_name as region_name, |total_amount, |total_count, |row_number() over(partition by year,month,dr.id order by total_amount desc) as sequence, |year,month |from t2 |left join dwd.dim_province dp on dp.id = t2.province_id |left join dwd.dim_region dr on dr.id = dp.region_id |""".stripMargin) t1.show() t1.write.mode("overwrite") .saveAsTable("dws.province_consumption_day_aggr") sql( """ |with t1 as ( |select |region_id, |sum(total_amount)/sum(total_count) as regionavgconsumption |from dws.province_consumption_day_aggr |group by region_id), t2 as ( |select |province_id as provinceid, |province_name as provincename, |total_amount/total_count as provinceavgconsumption, |t1.region_id as regionid, |region_name as regionname, |t1.regionavgconsumption as regionavgconsumption |from dws.province_consumption_day_aggr pcda |left join t1 on pcda.region_id = t1.region_id) |select t2.*, |case | when provinceavgconsumption>regionavgconsumption then '高' | when provinceavgconsumption=regionavgconsumption then '相同' | when provinceavgconsumption<regionavgconsumption then '低' end |from t2 |""".stripMargin).createOrReplaceTempView("t2TableTemp") mysqlTempTable(spark,"provinceavgcmpregion") sql( """ |insert overwrite table mysql_provinceavgcmpregion |select * from t2TableTemp |""".stripMargin)
sql( """ |select |region_id, |region_name, |province_id, |province_name, |total_amount, |row_number() over(partition by region_id order by total_amount desc) as threeprovince |from dws.province_consumption_day_aggr |""".stripMargin).where("threeprovince<=3").drop("threeprovince").createOrReplaceTempView("t3Temp") sql( """ |select |region_id, |region_name, |concat_ws(',',collect_set(cast(province_id as string))) as provinceids, |concat_ws(',',collect_set(province_name)) as provincenames, |concat_ws(',',collect_set(cast(total_amount as string))) as provinceamount |from |t3Temp |group by region_id,region_name |""".stripMargin).createOrReplaceTempView("t333") mysqlTempTable(spark,"regiontopthree") sql( """ |insert overwrite table mysql_regiontopthree |select * from t333 |""".stripMargin)
defmysqlTempTable(sparkSession: SparkSession, mysqlName: String): Unit = { val url = "jdbc:mysql://172.16.42.128/shtd_result?useSSL = false" val driver = "org.mariadb.jdbc.Driver" val user = "root" val password = "admin" sparkSession.read.format("jdbc") .option("url", url) .option("driver", driver) .option("user", user) .option("password", password) .option("dbtable", mysqlName).load().createTempView(s"mysql_$mysqlName") } } }
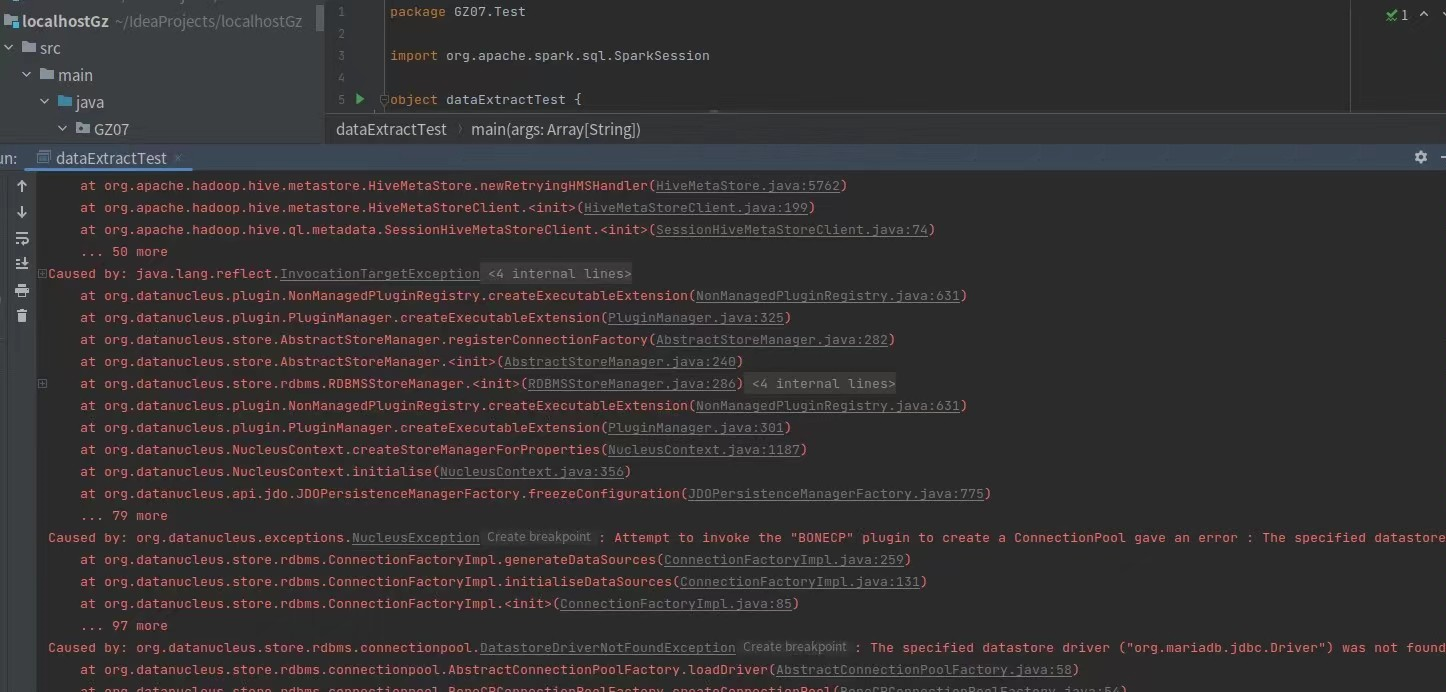
BUG点
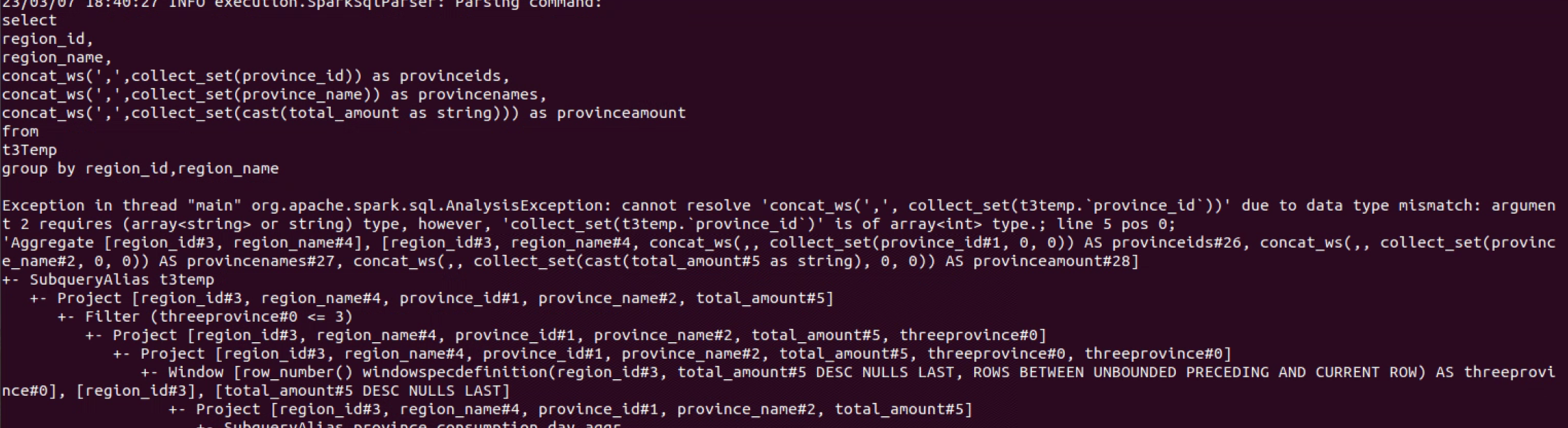
指标计算最后一题的时候,是之前没怎么做过的类型,是列转行,想起来了collect_set和concat_ws两个方法能实现任务目标,但是报错了,看报错信息,明白了似乎是province_id的类型不对需要是array 或者是string,就去用cast (xxx as string)转换成string再放进去,问题解决。
扩展学习
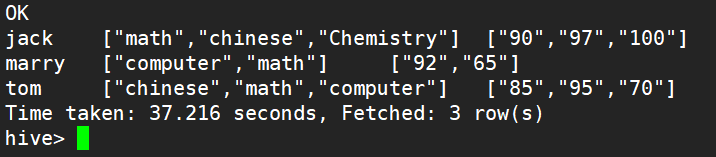
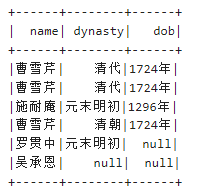
想得到这样的表
多行变一行 有公共列
1).先使用collect_set函数使多行成为一行数组
1 2 3
hive> select name,collect_set(subject) res1 , > collect_set(cast(score as string)) res2 > from stu group by name;
2). 加上concat_ws函数可以取出数组中的每一个元素的值在用分隔符连接
1 2 3
hive> select name,concat_ws('@',collect_set(subject)) res1 , > concat_ws('-',collect_set(cast(score as string))) res2 > from stu group by name;
//TODO t1 sql( """ |with t1 as ( |select |final_total_amount, |province_id, |substring(etl_date,4,0) as year, |substring(etl_date,5,2) as month |from |dwd.fact_order_info), |t2 as ( |select |province_id, |sum(t1.final_total_amount) as total_amount, |count(1) as total_count, |year,month |from |t1 |group by province_id,year,month) |select |t2.province_id as province_id, |dp.name as province_name, |dr.id as region_id, |dr.region_name as region_name, |t2.total_amount, |t2.total_count, |row_number() over(partition by year,month,region_id order by total_amount desc) as sequence, |year,month |from |t2 |left join dwd.dim_province dp on dp.id = t2.province_id |left join dwd.dim_region dr on dr.id = dp.region_id |""".stripMargin).write.mode("overwrite") .saveAsTable("dws.province_consumption_day_aggr")
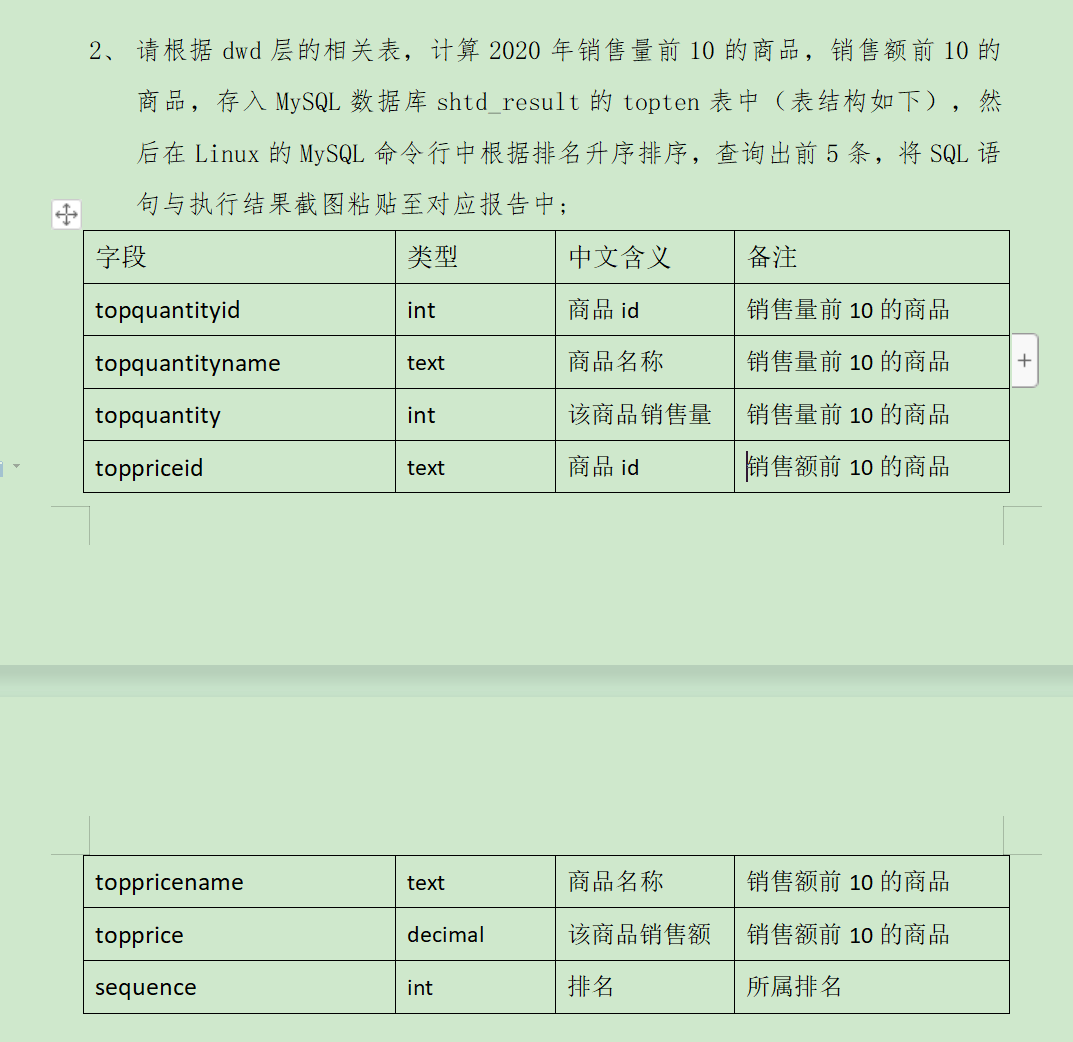
//TODO t2 sql( """ |with t1 as ( |select |sku_id,sku_name,order_price,cast(sum(sku_num) as int) as skuSum, |cast(sum(sku_num)*order_price as int) as skuOrderSum |from |dwd.fact_order_detail |group by sku_id,sku_name,order_price), |t2 as ( |select |t1.sku_id as topquantityid, |t1.sku_name as topquantityname, |t1.skuSum as topquantity, |row_number() over(order by t1.skuSum desc,t1.sku_id) as topTenQuantity |from |t1 |limit 10), |t3 as ( |select |t1.sku_id as toppriceid, |t1.sku_name as toppricename, |t1.skuOrderSum as topprice, |row_number() over(order by t1.skuOrderSum desc) as sequence |from |t1 |limit 10) |select topquantityid, |topquantityname, |topquantity, |t3.* |from |t2 |left join t3 on t2.topTenQuantity=t3.sequence |order by t3.sequence |""".stripMargin).createOrReplaceTempView("t2") mysqlTempTable(spark,"topten") sql( """ |insert overwrite table mysql_topten |select * from t2 |""".stripMargin)
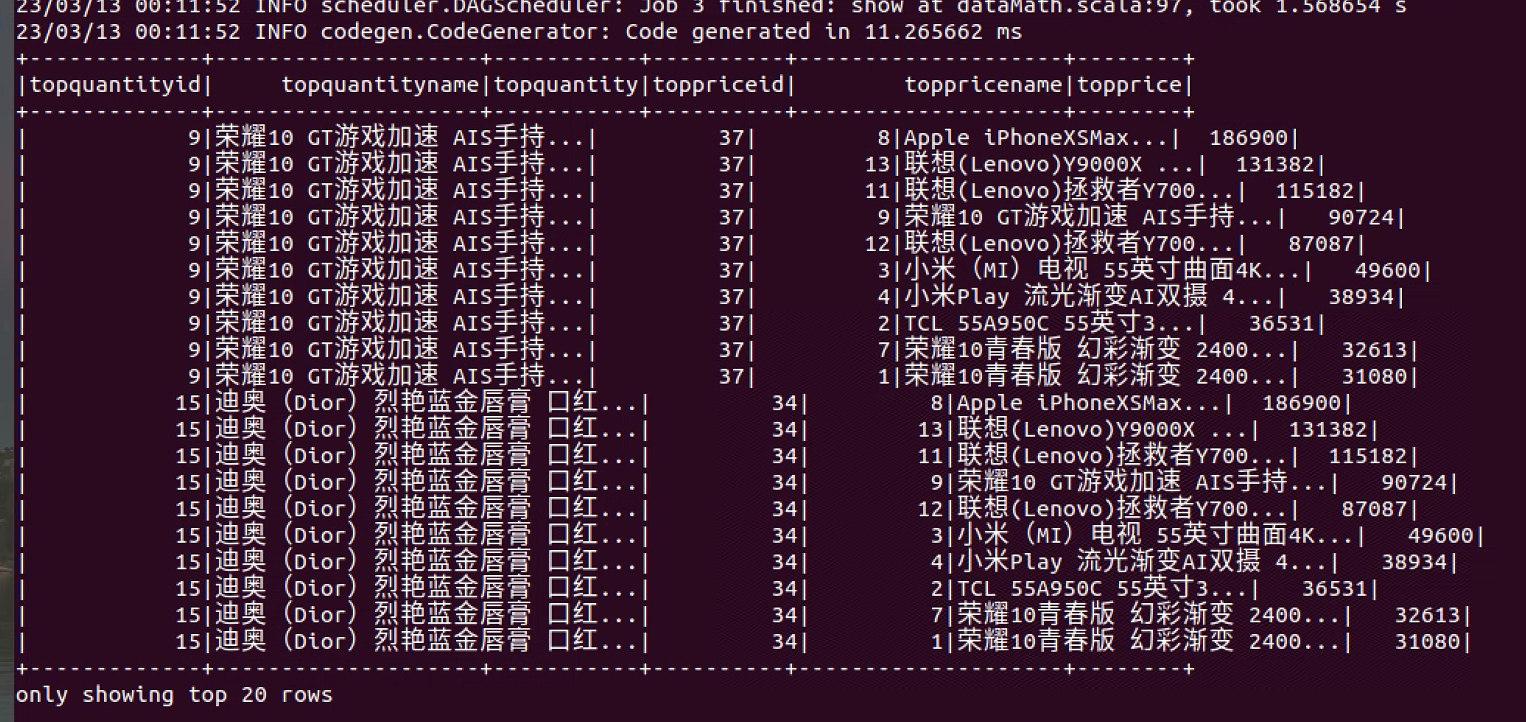
//TODO t3 sql( """ |with t1 as ( |select |foi.province_id as provinceid, |dp.name as provincename, |dr.id as regionid, |percentile(cast(final_total_amount as bigint),0.5) as provincemedian |from |dwd.fact_order_info foi |left join dwd.dim_province dp on dp.id = foi.province_id |left join dwd.dim_region dr on dr.id = dp.region_id |group by foi.province_id,dp.name,dr.id), |t2 as ( |select |dr.id as regionid, |dr.region_name as regionname, |percentile(cast(final_total_amount as bigint),0.5) as regionmedian |from |dwd.fact_order_info foi |left join dwd.dim_province dp on dp.id = foi.province_id |left join dwd.dim_region dr on dr.id = dp.region_id |group by dr.id,region_name |) |select t1.provinceid,t1.provincename,t2.regionid,t2.regionname, |t1.provincemedian,t2.regionmedian |from |t1 |left join t2 on t1.regionid = t2.regionid |""".stripMargin).createOrReplaceTempView("t3") mysqlTempTable(spark, "nationmedian") sql( """ |insert overwrite table mysql_nationmedian |select * from t3 |""".stripMargin)
mysql执行命令以及结果
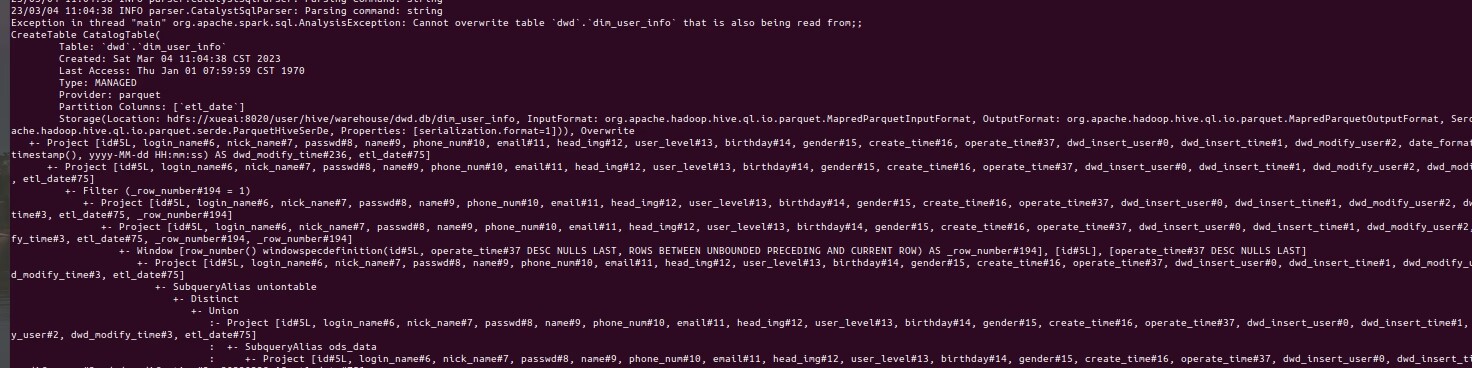
BUG点
想将两个表给合并起来,就想到了之前使用过的select t1.x,t2.x from t2,t3报了错误,看报错信息是hive不支持笛卡尔积的使用,在hive中开启笛卡尔积就能解决报错。开启方法如下在截图最后两行。如果放在spark中提交的话,还是会报错。报错信息是crossJoin也是笛卡尔,需要用如下的代码解决
sql( """ |with t1 as ( |select |final_total_amount, |province_id, |substring(etl_date,4,0) as year, |substring(etl_date,5,2) as month |from |dwd.fact_order_info), |t2 as ( |select |province_id, |sum(t1.final_total_amount) as total_amount, |count(1) as total_count, |year,month |from |t1 |group by province_id,year,month) |select |t2.province_id as province_id, |dp.name as province_name, |dr.id as region_id, |dr.region_name as region_name, |t2.total_amount, |t2.total_count, |row_number() over(partition by year,month,region_id order by total_amount desc) as sequence, |year,month |from |t2 |left join dwd.dim_province dp on dp.id = t2.province_id |left join dwd.dim_region dr on dr.id = dp.region_id |""".stripMargin).write.mode("overwrite") .saveAsTable("dws.province_consumption_day_aggr")
val l1: Long = sql( """ |select count(*) from dwd.fact_order_info |""".stripMargin).first().getLong(0) //已下单人数 println(l1+"*******************************************************************") val l2: Long = sql( """ |with t1 as( |select |user_id as userid, |cast(date_format(create_time,'yyyyMMdd') as int) as day, |final_total_amount |from |dwd.fact_order_info a), |t2 as ( |select |userid,day,sum(final_total_amount) as sumorder |from t1 |group by userid,day |),t3 as ( |select |a.userid, |concat(a.day,'_',b.day), |a.sumorder |from |t2 a |left join t2 b on a.userid=b.userid |where |a.day+1=b.day |and |a.sumorder<b.sumorder |) |select count(*) |from |t3 |""".stripMargin).first().getLong(0) //连续两天的人数 print(l2+"*******************************************************************") sql( s""" |select $l1 as purchaseduser, |$l2 as repurchaseduser, |concat(round($l2/$l1,3)*100,'%') as repurchaserate |""".stripMargin).show() //直接查 保留三位小数然后乘100加%就是百分比
val data = sql( """ |select |b.name,count(*) as con |from |dwd.fact_order_info a |join dwd.dim_province b on a.province_id=b.id |group by b.name |order by con desc |""".stripMargin) .rdd.map(x => (x.getString(0),x.getLong(1))) .collect().toList print(data) import spark.implicits._ val dum: DataFrame = Seq("1").toDF("dum") data.foldLeft(dum)((dum,d) => dum.withColumn(d._1,lit(d._2))) .drop("dum") .show(false)
//TODO t2 sql( """ |with t1 as ( |select |sku_id,sku_name, |cast(sum(sku_num) as int) as skuSum, |sum(final_total_amount) as topprice |from |dwd.fact_order_detail fod |join dwd.fact_order_info foi on foi.id=fod.order_id |group by sku_id,sku_name), |t2 as ( |select |t1.sku_id as topquantityid, |t1.sku_name as topquantityname, |t1.skuSum as topquantity, |row_number() over(order by t1.skuSum desc,t1.sku_id) as topTenQuantity |from |t1 |limit 10), |t3 as ( |select |t1.sku_id as toppriceid, |t1.sku_name as toppricename, |t1.topprice as topprice, |row_number() over(order by t1.skuOrderSum desc) as sequence |from |t1 |limit 10) |select topquantityid, |topquantityname, |topquantity, |t3.* |from |t2 |left join t3 on t2.topTenQuantity=t3.sequence |order by t3.sequence |""".stripMargin).createOrReplaceTempView("t2") mysqlTempTable(spark,"topten") sql( """ |insert overwrite table mysql_topten |select * from t2 |""".stripMargin)
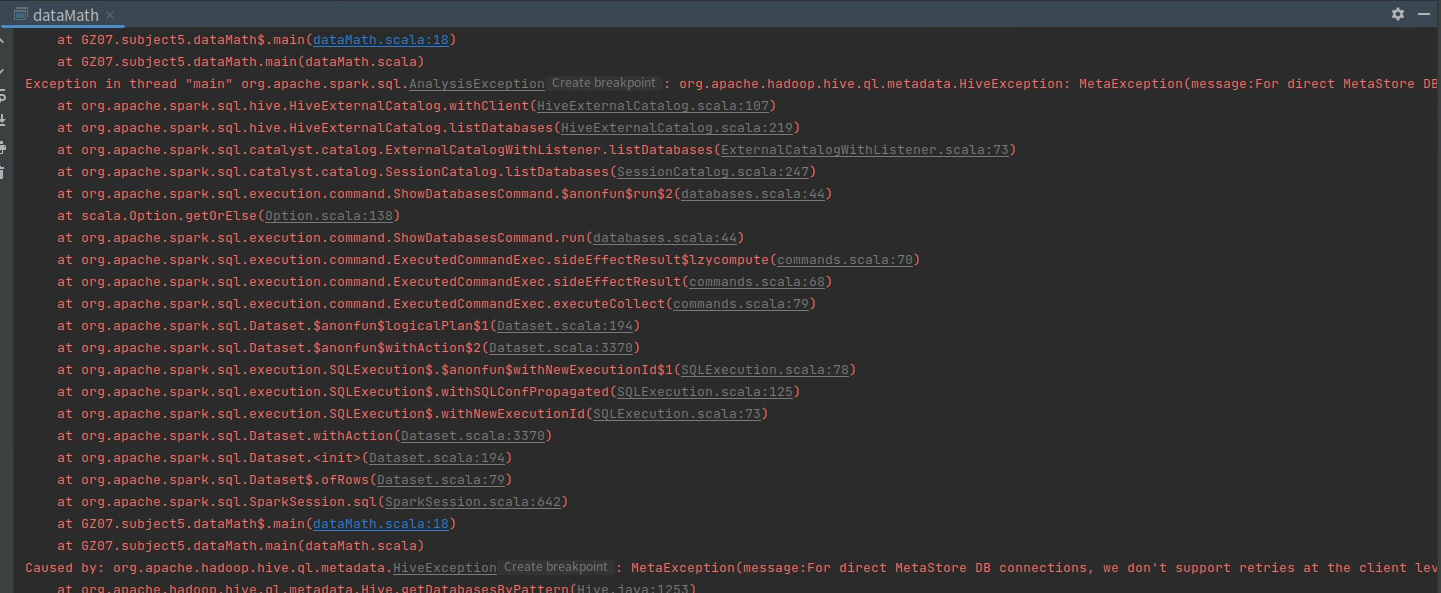
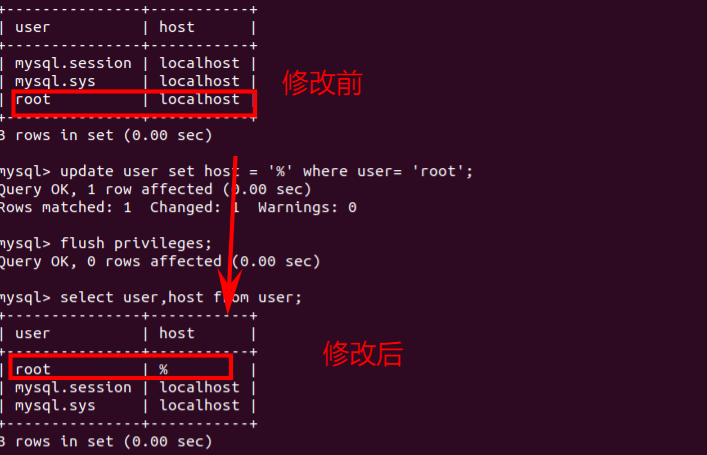
报错信息为截图,但是记住了。java.sql.SQLException: null, message from server: “Host ‘XXX‘ is not allowed to connect异常。是mysql拒绝了我的该网段的链接,是因为mysql中root用户只允许本地连接和 回环地址,之前IDEA无法直接运行的BUG也算是解决了。
解决步骤:
use mysql;
select user,host from user;
update user set host = ‘%’ where user = ‘root’;
flush privileges; --刷新权限
花了两三天的时间把Vue3基础给学习了,Vue3给我最直观的改变就是使用了composition API把setup作为舞台,将原来的vue2那种数据以及方法在不同生命周期地方,使用不同的方法,都放在了setup中,最后只要return就行了,和java和python中所定义的方法一样,里面有属性以及一些方法。而且代码看起来舒服很多,可读性对我而言强了,上手还是蛮快的,也没什么难点,生命周期部分也非常的知名见意,我觉得vue3的setup这样的写法还是很适合我的。而且原本Vue2中的语法在vue3中都是可以使用的,虽然官方不建议这么做,但是也能写能用,如果和Vue3有冲突的地方,会以Vue3为主,因为自己是使用vite创建的vue3工程,npm run dev跑起来真的比serve快了很多,打包也快了不少。我觉得Vue3的核心应该是响应式proxy,属性值的读写、属性的添加、属性的删除都可以通过proxy完成,所以我认为该点为核心部分,而且基本API都离不开proxy。