
大数据24年4月笔记
模版
学习日期:
所学内容概述
BUG
日总结
分栏标签外挂
1 | {% tabs 分栏%} |
四合服务器测试
学习日期: 4.3
所学内容概述
四合服务器测试
使用基本的spark测试是否能连接到服务器, 使用spark提交代码是否能连接到hive以及mysql
BUG
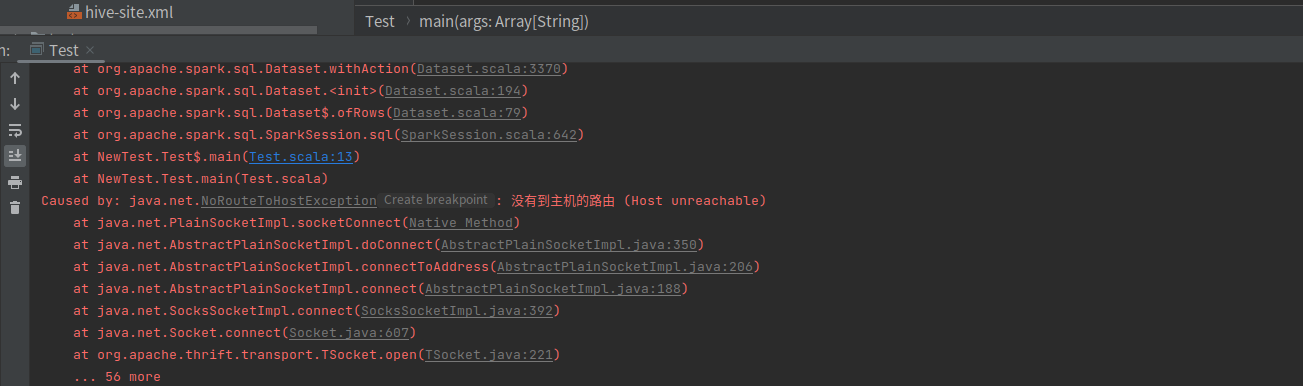
IDEA直接跑出现现在的报错,因为四合服务器似乎有两个ip地址,一个局域一个直连,我看里面他配的hosts映射是局域的,刚开始自己在自己电脑配置的是直连的,报了如下的错误,然后把自己电脑映射全改成服务器局域的,还是报错,打包放到服务器用spark提交,是好的,也不知道什么问题,因为自己ping 局域是ping不同的,未能解决。
日总结
今天服务器刚到,上午修改路由以及连交换机什么的,下午很晚服务器才能使用,而且没有外网,题也没练成,还出现了bug。这个bug之前遇到过,但是这服务器中集群都是有不一样ip,有直连和局域,所以也不知道映射应该挂哪一个,等明天再解决了。
蓝桥杯备赛算法
学习日期: 4.4
所学内容概述
1 | //手搓冒泡排序 |
BUG
解决昨天bug,今天报错变了Permission denied: user=anonymous, access=EXECUTE, inode=“/tmp“,我把本地映射全部设置成直连,报错信息变了,去启动了hive2,还是报错,看信息好像是tmp的权限,我先把本地的tmp文件chmod 777 没有什么用,然后去服务器把hdfs上面的tmp权限设置777,就正常了。

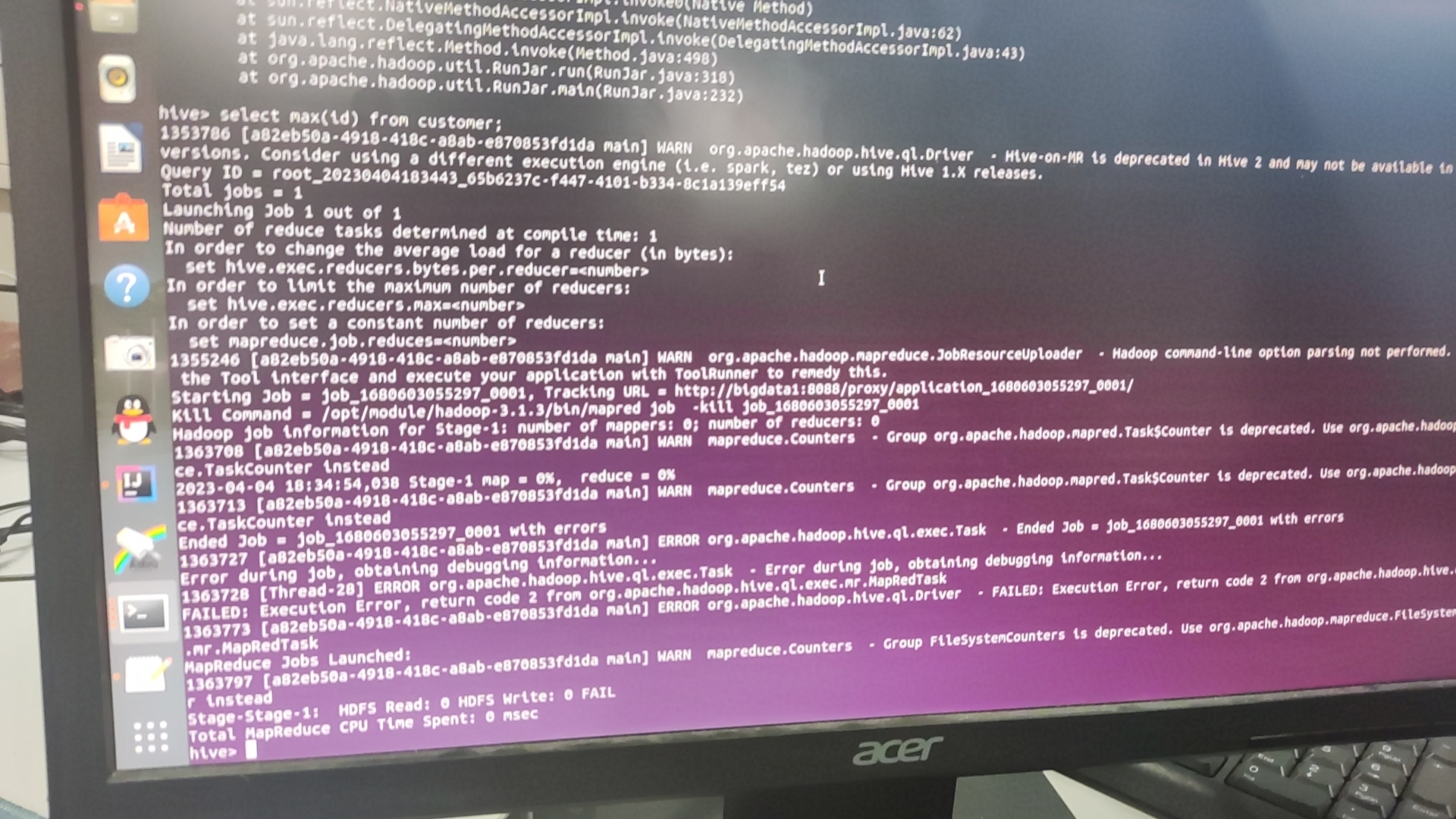
服务器正常配置好了,只用hive的时候发现,每次使用聚合函数hive cli的时候就会卡住,搜csdn发现也没有什么统一的解决办法,最多的是统一集群时间,但是自己不知道怎么查看整个集群的时间,看日志的时候,发现bigdata1主机好像比其他两个机子慢了1秒,在想这样也会有问题吗,如果要统一集群时间的话,要联网下命令,又因为服务器没网,这BUG就无法解决了,只能等四合老师回应了。
日总结
今天上午依旧在测试服务器机子是否可用性,解决了昨天bug,然后又新出来了bug,解决完以后,卡在hive的bug,问题描述在上面也有,上午得知无法解决,下午就去练蓝桥杯的题目了,从基础的算法开始了,做了七八题吧难度都挺简单的,基本都是C组前面的几题还没有上难度。后面花一天练一下贪心算法和二分感觉问题应该就不会很大了。
7月任务一
学习日期: 4.5
所学内容概述
任务一任务完成
1 | package gz07.subject1 |
1 | package gz07.subject1 |
1 | package gz07.subject1 |
BUG

如上报错,看信息是HiveFileFormat,想起来之前自己有个format(“Hive”)这个在saveAsTable的时候一直不知道加了有什么用,把这个加以后就没这个报错信息了。

如上报错信息,在存表的时候,看报错信息似乎是cast是类型转换,后面翻译是string到timestamp,感觉应该是说String类型的数据不能放在列为timestamp中意思,代码修改:如果是sql加的数据,类型使用cast( xx as timestamp )是比较常规的,如果是用withColumn添加的数据需要在第二个参数后面加.cast(“timestamp”)
日总结
今天再做7月任务书使用服务器做的,虽然和小白一样都是新版本,但是还是遇到不少BUG的,应该是在服务器中用了三台机子的原因,出现集群的BUG,好在看报错日志顺利解决了BUG,hive cli的问题还是没解决,不行的话只能用spark跑hive cli,然后用vim伪造截图了。
处理hive cli的BUG
学习日期: 4.6
所学内容概述
今天备战蓝桥杯的主要内容是递归,难点在回溯算法的使用,还不是很能弄懂,虽然有模版套,但是因为采用的是递归算法所以时间损耗很大,能解决前5题的问题。
算法代码
1 | public static void zuhe4(int step) { |
等边三角形题目
1 | static int num [] = new int[10]; |
回溯算法
回溯算法是一种深度优先搜索算法,所以深搜的特点回溯算法都有。一、它是一种递归算法。二、它是一种暴力算法。三、本质是穷举,穷举所有可能,然后找出我们想要的答案
1 | void backtracking(路径,选择列表,结果集...) { |
BUG
解决一旦使用hive cli就会报错的BUG,经过长达一天半的研究,只需要在yarn-site.xml中加入如下的配置即可,如果比赛环境也是如此的话,那真的太难为选手了。
1 | <property> |
日总结
今天上午的时间把hive cli的bug解决了,就是不知道比赛的时候该怎么办,这个配置文件只能先背下来了。如果比赛要求禁止修改环境的话,就把xml文件修改完,再弄回去好了。然后今天蓝桥杯备赛内容学了不擅长的递归,用到递归的经典算法回溯,也算是暴力的一种吧,其实用for循环也能做出来。还是后面的贪心和二分比较重要。
7月任务书四(改良版)
学习日期: 4.7 /4.10
所学内容概述
1 | package Julysubject.subject4 |
1 | package Julysubject.subject4 |
1 | package Julysubject.subject4 |
BUG
又报出类型不匹配的问题,我就很奇怪,我在sql中使用cast已经进行类型转换了,而且同样的sql语句在其他表能使用但是在这里就说没转换,加入表的语句也是一样的。后面把insertInto换成了saveAsTable没报错了,但是表内没有数据,然后又想起来是动态分区,是不是动态分区的原因,把partitionBy加到mode后面,数据也加入了报错解决。动态分区需要用saveAsTable,为什么insertinto不行,那是底层源码的问题了。

日总结
这两天做了7月任务4,周六做完以后,周一的时候跟其他学校的交流了一下,主要改了是清洗部分的代码,对于合并以后insert和modify的取值,进行了讨论以及调整,遇到了一个奇怪的BUG,解决了但是不知道为什么insert不行,就不纠结了。
修理clickHouse的BUG
学习日期: 4.11
所学内容概述
修BUG的一天
BUG
这是今天修改任务书四的指标计算部分的时候,连接表的时候的警告,对结果是没什么影响,然后因为警告看着很麻烦。找原因的时候发现,region和province中两个表联立的公共字段是region_id,但是region表中该字段是bigint,province中是string,又是一个坑,就把on后面 也使用cast转换类型就行了。

自己服务器的机子clickhouse都起不来,换了启动命令还是不行,把机子重置了几次,就好了,clickhouse-client -h bigdata1 —port 9001 —password 123456 没找到原因

日总结
今天修了一天的bug,上午把之前7月任务书四改良了一下,后面做任务书的时候就可以按照现在这样来写,这几天把7月的五个任务书都摸透了,指标计算的15题,下午想用clickhouse,结果一下午都没弄好,最后搞好了也没找到原因。
spark集成clickHouse
学习日期: 4.12
所学内容概述
准备ClickHouse测试数据
创建一个名为test的数据库,并在该数据库中创建一个名为visit的表,用于跟踪网站访问时长。
1)先运行以下命令,启动一个客户端会话:
目前服务器的clickhouse只有这条命令启动成功过。
1 | $ clickhouse-client -h bigdata1 --multiline --port 9001 --password 123456 |
2)通过执行以下命令创建test数据库:
1 | bigdata1 :) CREATE DATABASE test; |
3)确认要使用的数据库test:
1 | bigdata1 :) USE test; |
4)运行下面这个命令创建visits表:
1 | bigdata1 :) CREATE TABLE visits ( |
5)通过运行以下语句将几行示例网站访问数据插入到刚创建的visits表中:
1 | bigdata1 :) INSERT INTO visits VALUES (1, 10.5, 'http://example.com', '2019-01-01 00:01:01'); |
6)查询数据:
1 | bigdata1 :) SELECT * FROM visits; |
spark使用clickHouse的jdbc驱动
有三个版本的jdbc
- 0.3.1及之前的版本:驱动程序为ru.yandex.clickhouse.ClickHouseDriver。
- 0.3.2版本:驱动程序同时支持ru.yandex.clickhouse.ClickHouseDriver和com.clickhouse.jdbc.ClickHouseDriver两种。
- 0.4.x:驱动程序为com.clickhouse.jdbc.ClickHouseDriver。
因为自己的Maven只能装0.32的所以自己就只使用了0.32的
pom.xml导入配置
1 | <!--clickhouse--> |
在Spark中执行简单查询。
1 | mport org.apache.spark.sql.SparkSession |
插入数据(重点)
这里直接拿user_info导入clickhouse
1 | import org.apache.spark.sql.SparkSession |
BUG
这条报错也不知道啥意思,看到个ENGINE,发现别人集成的时候有一条配置.option(“createTableOptions”,”engine=log()”)加上以后报错就没了。

这个报错验证了很多次发现,只要导入clickhouse的时候,mode选择overwrite都会报错,不管是用saveAsTable还是Insertinto,赛规都是导入数据,使用append追加也是比较符合要求的,就没去修这个了。

日总结
今天上午的时候在修c昨天启动的bug, 后面重置了几次,发现没问题了,也不知道原因,下午试着去spark集成clickhouse除了Maven导入依赖的时候浪费了很久,其他还是挺顺利的,clickhouse和mysql不一样, 用saveAsTable是不会自动创建表的,所以如果要导入的话,必须要先在clickhouse建表。
操作hbase
学习日期: 4.13
所学内容概述
指标计算导入clickhouse
Clickhouse建表语句
和hive以及mysql不一样,类型不同,然后建表的时候必须要有ENGINE = MergeTree(),然后还要设置主键或者排序其他的任意函数,不然会提示报错。
1
2
3
4
5
6
7
8
9
10
11
12create table dws.province_consumption_day_aggr2 (
province_id UInt64,
province_name String,
region_id UInt64,
region_name String,
total_amount Float64,
total_count UInt64,
sequence UInt64,
year String,
month String
) ENGINE = MergeTree() --必须加
PRIMARY KEY province_id;
1 | package JulySubjectTestNew.subject5 |
写入Hbase
需要建立hbase表
建表语句理解:第一个字段称为表名,我的理解更像关系型数据库的库名,第二个字段叫做列族,我觉得就像普通数据库的表名了,添加的时候key相当于列名,value相当于值
1 | create 'panniuspark_user' ,'cf' |
1 | package com.hainiu.sparkhbase |
BUG
spark写入数据到hbase的报错,没找到原因。看样子似乎是依赖 版本的问题,也不知道是新了还是老了,索性就换其他方法写入了。

日总结
今天主要是想办法操作hbase,一直在搜spark操作hbase,因为转换成df的话,用rdd算子做起来方便很多,就不需要重复的建表语句,但是网上的方法实在是太多了,而且又难以理解,只是简单的插入编造的数据,这样显然是不行的,所以在网上找了一天也没有找到比较好的,改天再试下别的使用方法。
hive外部表关联hbase以及指标计算
学习日期: 4.15
所学内容概述
任务书5和任务书3的指标计算
1 | package JulySubjectTestNew.subject3 |
1 | package JulySubjectTestNew.subject5 |
BUG
BUG1
使用如下建表语句的时候,发现必须要有hive必须要有一个列的值和:key是一样的,否则就会报错
1 | create external table students( |
日总结
今天上午的时候把hbase和hive的关联表连接完成了,能使用外部连接hbase,也可以建立hbase和hive的关联表,区别就是外部表,相当于hive是一个查看器,外部表的话删除hive,hbase依旧存在。关联表就相当于是镜子,不管如何改变这两个任何一个,另一个都会改变。下午的时候把做了6道指标计算题,任务3和任务5的指标计算还是算难点的,所以还是浪费了一些时间的。
数据导入以及hbase抽取df测试
学习日期: 4.20
所学内容概述
将数据导入hbase
- 抽取ods部分数据到hbase
1 | package mock |
抽取hbase数据并转换dataframe
这种办法其实很麻烦,但是也没有什么比较好的办法了,外部表据说是数据会丢失一部分,所以保险起见还是使用这种方法吧。首先要创建一个类,类的参数要和你想要抽成的df表对应好,然后连接hbase模式为INPUT_TABLE,一个一个字段的抽出来,用map放类中,然后用implicit隐式转换toDF,转换成dataframe类型,就能操作了。
1 | private case class OrderDetail(order_detail_id: String, order_sn: String, product_id: String, product_name: String, product_cnt: String, product_price: String, average_cost: String, weight: String, fee_money: String, w_id: String, create_time: String, modified_time: String, dwd_insert_user: String, dwd_insert_time: String, dwd_modify_user: String, dwd_modify_time: String, etl_date: String) |
BUG
今日无BUG
日总结
今天的主要任务是总结从长沙学到的东西吧,学到的这种转hbase的办法比赛还是可以用的,因为自己之前虽然是有外部表,方便一点,但是数据多了的确是会丢失的,还是使用这样的办法比较安全。自己也是反复敲了很多遍,也学会了吧,自己也能敲出来,但是还没全部敲出来过,比较字段实在是太多了。
省赛任务书模拟
学习日期: 4.22
所学内容概述
抽取部分,难度不大,两个方法基本全部11个表都能抽取
1 | package huNanSubject |
清洗部分在这任务书中,三块里面最难最费时间的了,又要从hbase又要从ods,有增量有全量,所以这块还是很耗时间的,尤其是hbase的时候,太麻烦了,每个字段都要写
1 | package huNanSubject |
指标计算这三题都蛮简单的,三题加起来才40分钟基本就做完了注意的点就是订单状态要看取哪个
1 | package huNanSubject |
BUG
基本无BUG,除了太卡了。
日总结
今天是做任务书,小结一下,一共做了将近5个小时,大概3个小时可能都是在导假数据,因为hbase和hive中都没有数据,然后昨天是不知道今天需要的表的,所以就现导了,也是出现了些问题的,类型和表字段不一样多各种问题,自己估摸了一下如果比赛的话这一套差不多3个小时自己就能做完。hbase那块还是要再去熟悉一下。
clickhouse不建表导入
学习日期: 4.24
所学内容概述
导入clickhouse 的方式,不建立临时表,直接用jdbc导入,properties中set除了url的基本配置,jdbc方法不用建表,会自动在clickhouse建表,列名为设置的列名
1 | package huNanSubject |
BUG
把之前在ubuntu写的代码,放自己电脑上面发现直接报错,然后发现了是scala版本的问题,xml中版本是2.12,自己电脑中是2.11的所以报了token的错误。

日总结
今天又复盘了一下任务书,然后将导入clickhouse放到一个工具类中,感觉mysql也可以放这工具类中,不知道导入mysql的时候如果不建表用这种方法行不行,一般从mysql抽数据到hive还是使用建立临时表的方法吧,毕竟这样比较熟悉, 导入一般也不会报错。比赛的时候可以把一些方法全部放到一个工具类中,写入的时候直接调用封装好的方法就行,还是能节省下很多时间的。
湖南任务书重做
学习日期: 4.26
所学内容概述
重新从头做了一下任务书并把一些题目给修改了。
BUG
报了这个错误,翻译是会为null的字段,无法导入非null字段,应该没有特意设置过这四个字段为非null,导入的时候就很奇怪报了这个错误,想了想去把保存方式从write.format(“hive”).partitionBy(“etl_date”).mode(“append”).saveAsTable(“dwd.dim_customer_inf”)
改成了write.format(“hive”).insertInto(“dwd.dim_customer_inf”),两种导入的结果在表存在并设置分区的情况下,结果是一样的,应该是saveAsTable方法的一个bug了。

日总结
今天再又去做了一遍任务书,将自己原数据都没有都10月1号改成了8月22,发现modified_time最少的数据都有800多条,所以就查了10条,然后就自己对hbase的抽取,因为一个一个字段要敲,比较麻烦,敲hbase都花费了十来分钟,还是挺浪费时间的,不过比赛6个小时的话,还是来得及的。预估能在4小时之内完成并截图。
赛前测试
学习日期: 4.27
所学内容概述
赛前对自己做过的任务书进行梳理,感觉hbase比赛提供好的话,类型可能是要转换的,或者自己额外建一个表都是String的。
BUG
这个小BUG其实问题不大,就是说没使用分组的时候,直接count会显示0。可以按照主键分组,然后max(count(*)),解决这个问题,但是可以设置参数直接让它可用,https://www.cnblogs.com/muyue123/p/14371799.html这里有方法说明
1 | set hive.compute.query.using.stats=false; |

日总结
今天晚上又去做了一下前面部分的清洗和抽取,把该记住的配置都再加深一个印象,像导入clickhouse以及mysql的driver还有url都要多次加强一下印象,还有需要修改的配置信息,yarn也要再过一遍,希望明天好好发挥即可。





