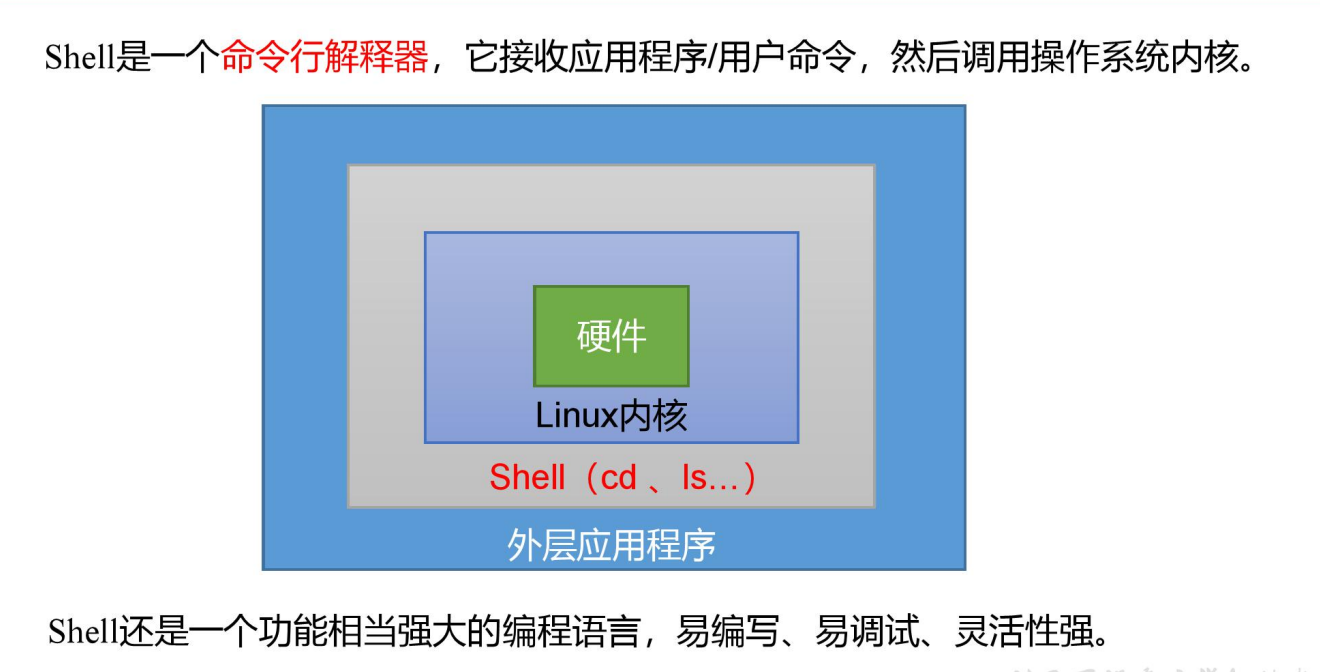
7.7 linux入门 基础
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
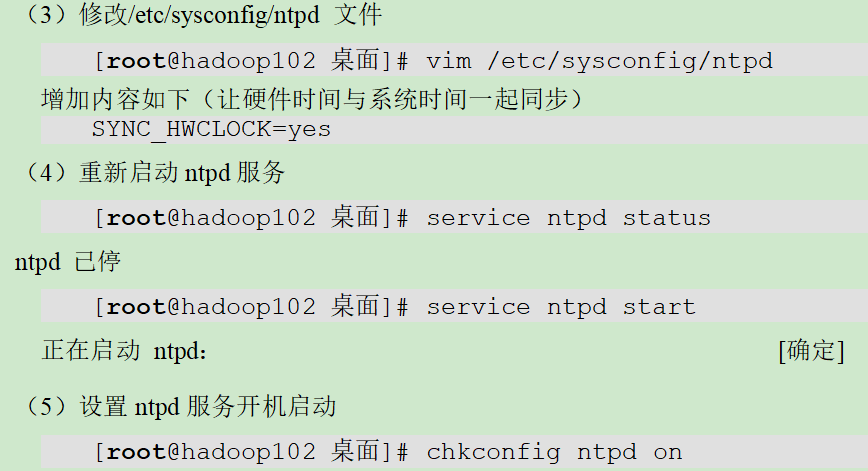
2.标题
P1001_课程介绍
3.所学内容概述
Linux 文件与目录结构 VI/VIM 编辑器(重要) 网络配置 系统管理
4、根据概述分章节描述
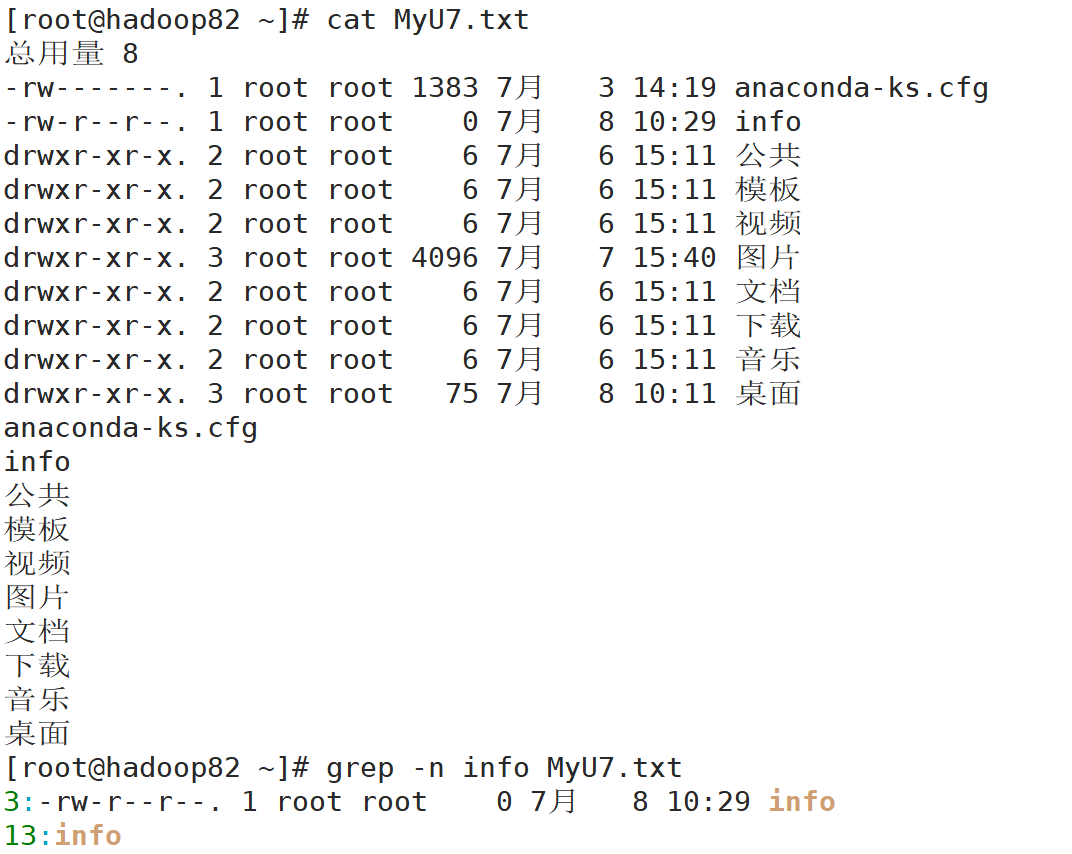
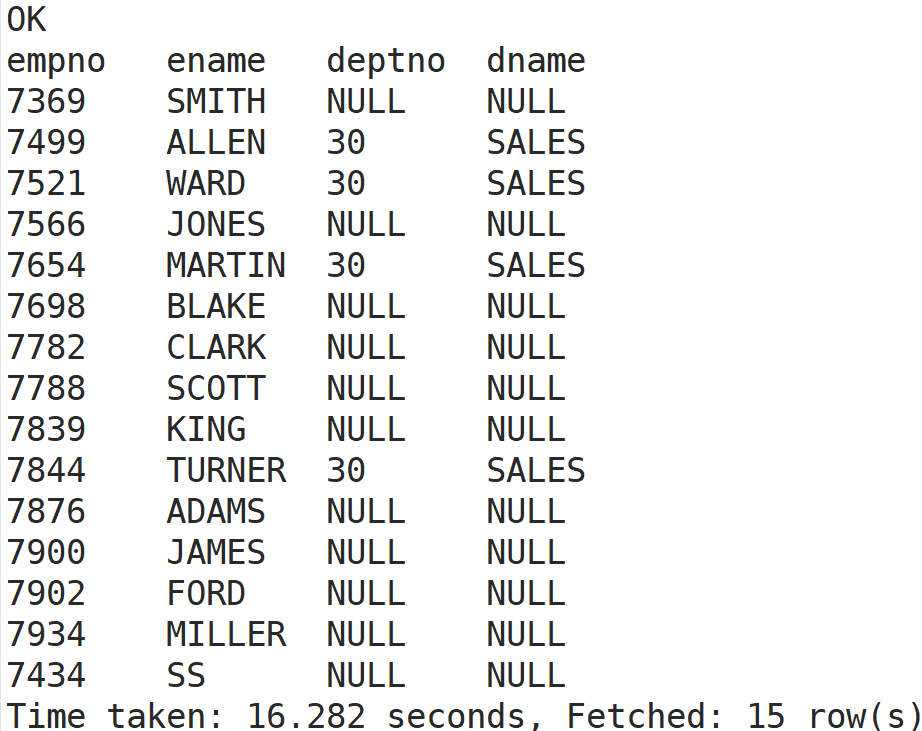
Linux 文件与目录结构 比较总结的一句话,Linux系统中一切皆文件。一些代码
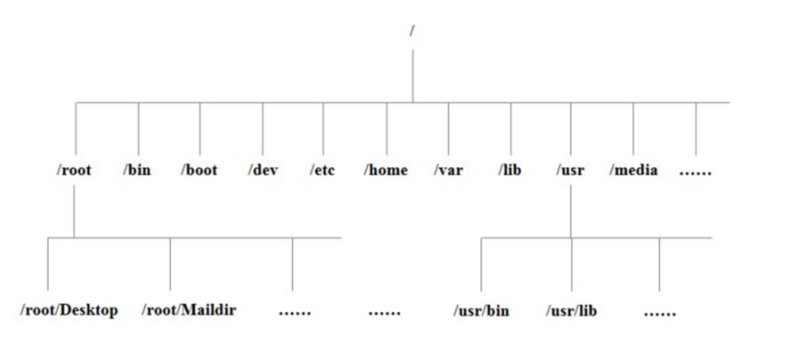
Linux内计算机文件目录如图所示
注意:带箭头是链接,查看属性可以找到其所指向目录
目录结构(树形图)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 常见目录说明 ①. /bin :存放常用命令(即二进制可执行程序) ②. /etc :存放系统配置文件 ③. /home :所有普通用户的家目录 ④. /root :管理员用户的家目录 ⑤. /usr :存放系统应用程序及文档 ⑥. /proc :虚拟文件系统目录,以进程为单位存储内存的映射 ⑦. /dev :存放设备文件 ⑧. /mnt :临时挂载点 ⑨. /lib :存放库文件 ⑩. /boot :系统内核及启动有关的文件 ⑪. /tmp :存放各种临时文件,是所有用户均可访问的地点 ⑫. /var :存放系统运行中常改变的文件,如系统日志
VI/VIM 编辑器(重要) 简介
1 2 VI 是 Unix 操作系统和类 Unix 操作系统中最通用的文本编辑器。 VIM 编辑器是从 VI 发展出来的一个性能更强大的文本编辑器。可以主动的以字体颜 色辨别语法的正确性,方便程序设计。VIM 与 VI 编辑器完全兼容
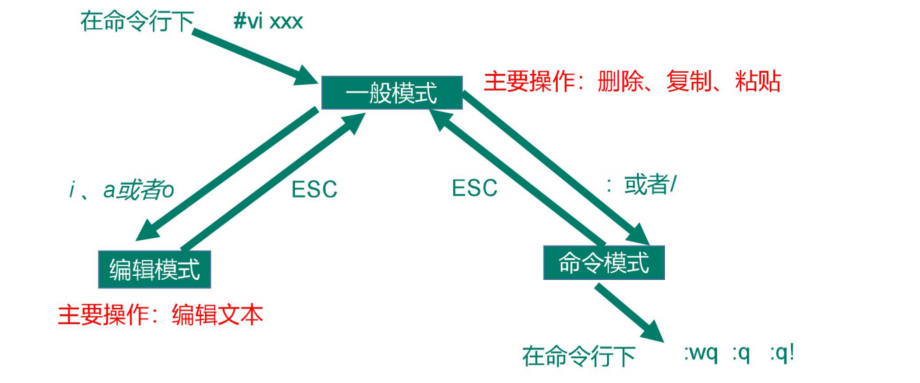
VI/VIM编辑器分为三个模式,一般模式,编辑模式和命令模式可以互相转换(默认进入是一般模式)
一般模式
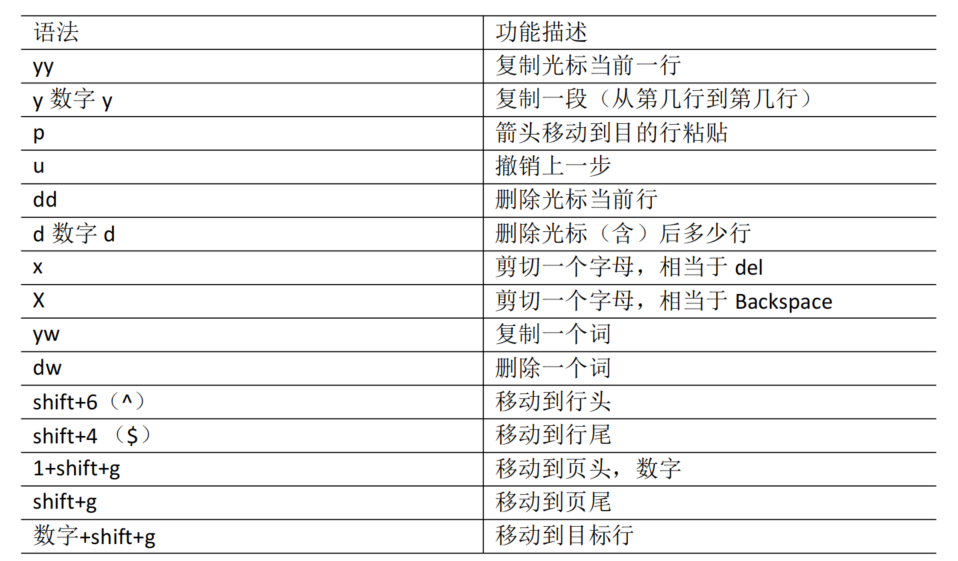
语法,使用指南
编辑模式
和windows中的记事本差不多,弥补一般模式中无法编辑文件内容的缺点
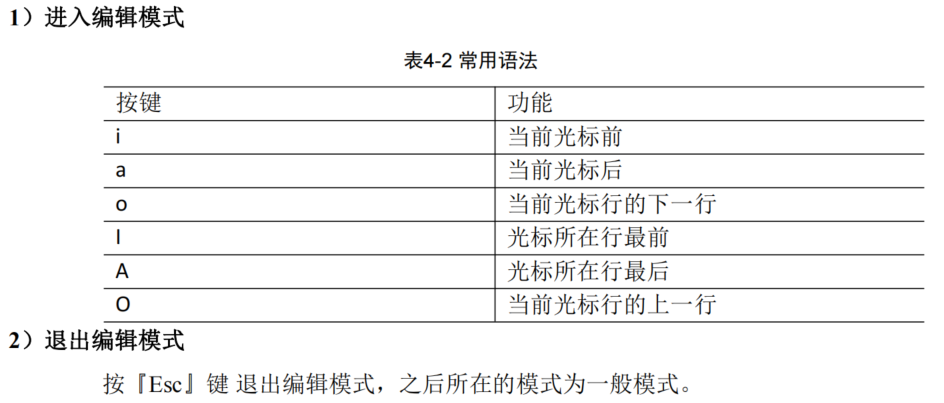
1 在一般模式中可以进行删除、复制、粘贴等的动作,但是却无法编辑文件内容的!要 等到你按下『i , I , o, O, a , A 』等任何一个字母之后才会进入编辑模式
[ESC]退出编辑模式到一般模式
指令模式 在一般模式当中,输入『 : / ?』3个中的任何一个按钮,就可以将光标移动到最底下那 一行
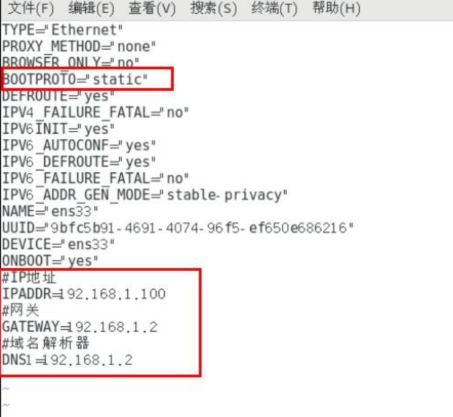
网络配置 查看网络 IP 和 网关 VMware自带虚拟网络编辑器,可以修改和查看IP地址和网关,在虚拟机便签里
配置网络ip地址
查看ip地址(Linux)
修改 IP 地址 1 [root@hadoop100 桌面]#vim /etc/ sysconfig/network-scripts/i fcfg-ens33
先把自动改成静态的,然后添加ip和网关和DNS,终端输入执行 service network restart
然后ping下主机,主机ping下linux,正常即可
修改主机名称
1 [root@hadoop100 桌面]# vi /etc/hostname
修改完reboot重启
下载了xshell和xfip
远程登录工具
系统管理 系统管理一些基本命令CSDN上面都有
Linux 中的进程和服务 计算机中,一个正在执行的程序或命令,被叫做“进程”(process)。
启动之后一直存在、常驻内存的进程,一般被称作“服务”(service)
systemctl
在centos7中systemctl是很重要的查看命令
常用关机重启命令如下
这个在后面还是少用,老是说在linux中大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
5.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
开始学习linux,因为之前学python用过一段时间的ubuntu,都是基于linux系统的,一些基本命令都是互通的,查看ls之类的,上手很快,今天学习内容比较简单,入门篇和基础篇,了解到linux一切皆文件,比较有意思,重点中的难点没有,VI和VIM命令记住的话,重点就搞定了,网络配置花了会时间,最后下午把系统管理中重要的命令自己多敲了几遍,今天学习状态还可以,也没有什么地方卡住很久,没出BUG,把ubuntu换到了18.04。
7.8 实操篇 文件和用户管理
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
P28028_实操篇_Shell命令整体介绍及帮助命令
3.所学内容概述
帮助命令
文件目录类
时间日期类
用户管理命令
用户组管理命令
文件权限类
搜索查找类
压缩和解压类
磁盘查看和分区类
进程管理类
4、根据概述分章节描述
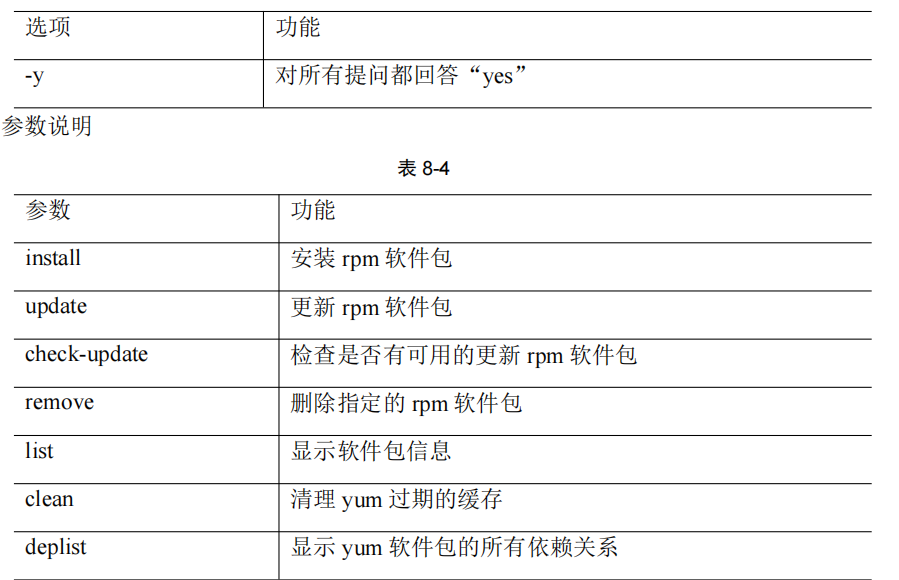
帮助命令
man help
后面跟命令或配置文件 help只能显示内置的而且是全英文
下载了man中文包,推荐自己使用man,相当于自带的一个tools查看
文件目录类
pwd
显示当前目录的绝对路径pwd
ls
查看目录文件
显示说明
每行列出的信息依次是:文件类型与权限 链接数 文件属主 文件属组 文件大小用byte
来表示 建立或最近修改的时间 名字
-a 全部的文件,连同隐藏档( 开头为 . 的文件) 一起列出来(常用)
-l 长数据串列出,包含文件的属性与权限等等数据;(常用)等价于“ll”
语法
cd
切换目录
基本用法
创建 删除 查找文件以及目录
创建
mkdir 文件夹名
特殊用法 -p多级创建目录
mkdir -p hello/world/java
删除
只能删除空的目录
rmdir 文件夹名
创建文件
touch 文件名只带文件名默认是文本文件
可加路径 touch 注意:命令后面 直接有/就是绝对路径 否则是相对路径
删除文件
rm 文件名
会提示是否删除 输入yes或者y 或者加入 -f 强制删除就没有提示了 rm -rf强制删除文件内所有目录
删库跑路 rm -rf /*不要尝试!
复制文件
cp
递归复制 -r
取消提示 /cp
移动文件
mv
查看文件
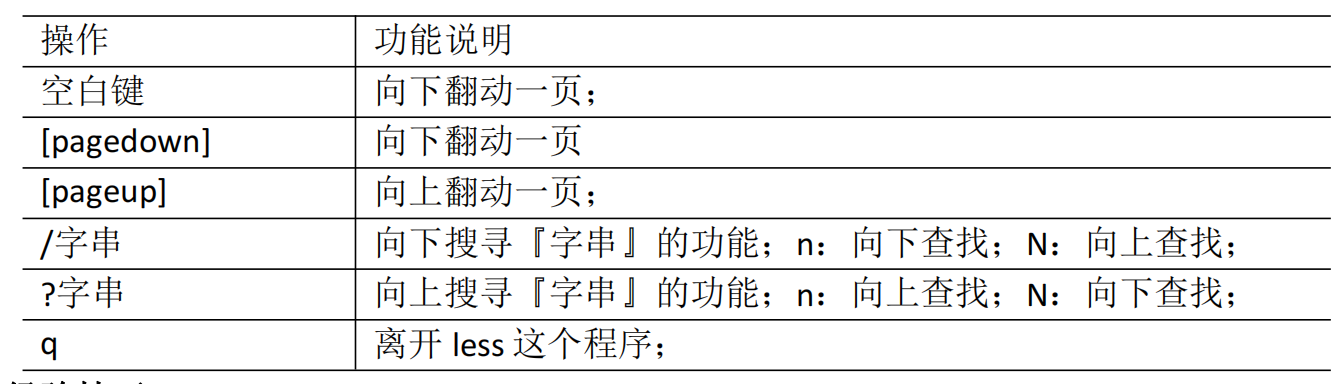
cat more less
推荐使用less
less 指令用来分屏查看文件内容,它的功能与 more 指令类似,但是比 more 指令更加 强大,支持各种显示终端。less 指令在显示文件内容时,并不是一次将整个文件加载之后 才显示,而是根据显示需要加载内容,对于显示大型文件具有较高的效率。
1 2 3 4 5 6 "less -e" 当文件显示结束后,自动离开,无需输入"q" "less -f" 强迫打开特殊文件,例如外围设备代号、目录和二进制文件"less -m" 显示类似more 命令的百分比"less -N" 显示每行的行号"less -s" 将连续的空行合并成一行显示"less -S" 行信息过长时,将超出部分舍弃
操作说明
=可以查看信息
g回到开头 G到最后一行
输出重定向
echo
后面跟什么控制台输出什么
-e 转义可用
echo -e "hello \nworld"
tail
输出文件尾部内容
重要点是tail -f 文件实时追踪该文档的所有更新内容
在开发环境调试程序,看实时日志很有用的。
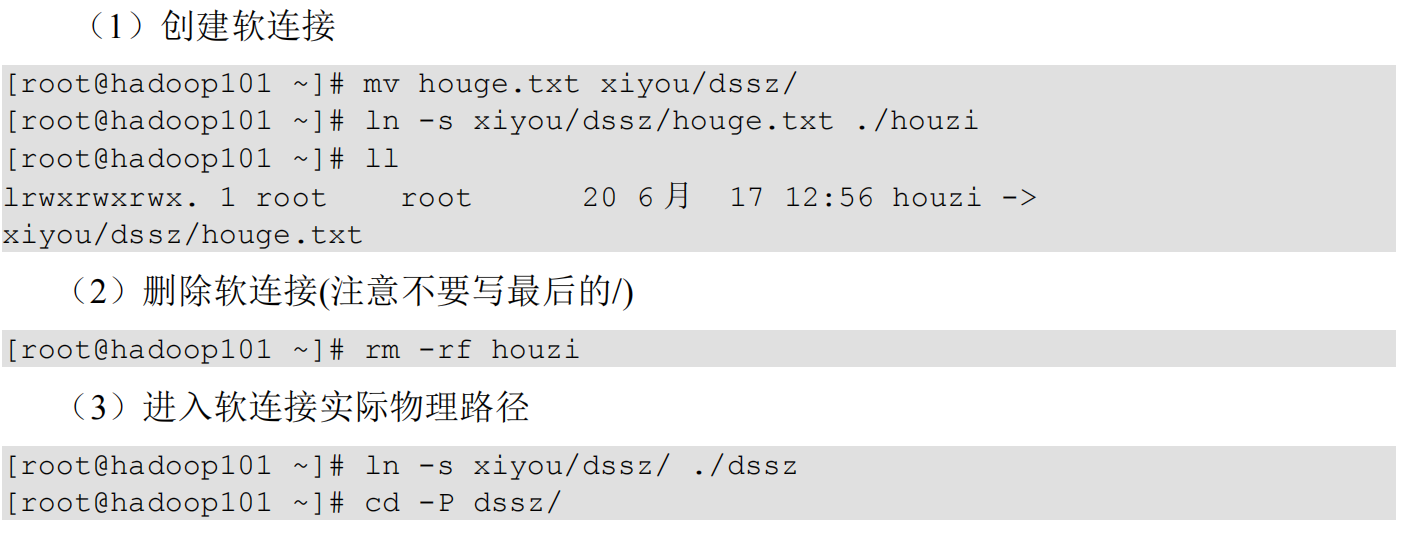
软链接
软链接也称为符号链接,类似于 windows 里的快捷方式,有自己的数据块,主要存放 了链接其他文件的路径
基本语法
ln -s [原文件或目录] [软链接名] (功能描述:给原文件创建一个软链接)
删除和查询
删除软链接: rm -rf 软链接名,而不是 rm -rf 软链接名/
如果使用 rm -rf 软链接名/ 删除,会把软链接对应的真实目录下内容删掉
查询:通过 ll 就可以查看,列表属性第 1 位是 l,尾部会有位置指向。
查看历史命令
history在终端敲过的所有命令
时间日期类
主要就是date命令很简单
1 2 3 4 5 6 7 date (功能描述:显示当前时间) (2 )date +%Y (功能描述:显示当前年份) (3 )date +%m (功能描述:显示当前月份) (4 )date +%d (功能描述:显示当前是哪一天) (5 )date "+%Y-%m-%d %H:%M:%S" (功能描述:显示年月日时分秒) (1 )date -d '1 days ago' (功能描述:显示前一天时间) (2 )date -d '-1 days ago' (功能描述:显示明天时间)
cal 查看本月日期 cal 2003查看2003年日历
用户管理命令
1 2 3 4 5 6 7 8 9 10 11 12 useradd 用户名 passwd 用户名 id 用户名 cat /etc/passwd su 用户名称 (功能描述:切换用户,只能获得用户的执行权限,不能获得环境变量) su - 用户名称 (功能描述:切换到用户并获得该用户的环境变量及执行权限) userdel 用户名 userdel -r 用户名 who查看登录用户信息 whoami (功能描述:显示自身用户名称) who am i (功能描述:显示登录用户的用户名以及登陆时间) usermod -g 用户组 用户名
利用sudo命令给用户root权限
需要修改配置文件
文件权限类
认识文件权限
(1)0 首位表示类型
在Linux中第一个字符代表这个文件是目录、文件或链接文件等等
- 代表文件 d 代表目录 l 链接文档(link file);
2)第1-3位确定属主(该文件的所有者)拥有该文件的权限。—User
3)第4-6位确定属组(所有者的同组用户)拥有该文件的权限,—Group
4)第7-9位确定其他用户拥有该文件的权限 —Other
rew在文件和目录的解释
(1)作用到文件:
[ r ]代表可读(read): 可以读取,查看
[ w ]代表可写(write): 可以修改,但是不代表可以删除该文件,删除一个文件的前 提条件是对该文件所在的目录有写权限,才能删除该文件
[ x ]代表可执行(execute):可以被系统执行
2)作用到目录:
[ r ]代表可读(read): 可以读取,ls查看目录内容
[ w ]代表可写(write): 可以修改,目录内创建+删除+重命名目录
[ x ]代表可执行(execute):可以进入该目录
1 2 3 4 5 chmod改变权限 第一种方式变更权限 chmod [{ugoa}{+-=}{rwx}] 文件或目录 第二种方式变更权限 chmod [mode =421 ] [文件或目录] 第二种经验 r =4 w =2 x =1 rwx =4+2+1=7 rw =4+2=6
修改所属组和用户(注意权限)
1 2 3 4 5 6 所属用户 递归-R chown [root@hadoop82 hello] [root@hadoop82 hello] 总用量 208 -rw-r--r--. 1 sjh2 root 41 7 月 7 10 :00 123 .txt
1 2 3 4 5 6 所属组 chgrp [root@hadoop82 hello] [root@hadoop82 hello] 总用量 208 -rw-r--r--. 1 sjh2 sjh2 41 7月 7 10:00 123.txt
搜索查找类
find查找文件或者目录
1 2 3 find -name info find /root -name "*.cfg" (在root目录下结尾是cfg的文件)find /home -size +204800/home目录下查找大于200m的文件)
locate 快速定位文件路径
locate 指令利用事先建立的系统中所有文件名称及路径的 locate 数据库实现快速定位给 定的文件。Locate 指令无需遍历整个文件系统,查询速度较快。为了保证查询结果的准确 度,管理员必须定期更新 locate 时刻。updatedb
grep 过滤查找及 **“|” **管道符
-n显示匹配行以及行号
1 2 ls | grep .txt(当前目录中以有.txt的文件)wc 查找显示行数 单词 字节
压缩和解压类
最常用的打包tar
tar [选项] XXX.tar.gz 将要打包进去的内容 (打包目录,压缩后的文件式.tar.gz)
1 2 3 4 tar -zcvf hello.tar .gz hello/ 1 .jpg 将hello目录和1 .jpg图片打包压缩 tar -zxvf hello.tar .gz -C /tmp 将hello.tar .gz压缩包,解压到tmp目录下
磁盘查看和分区类
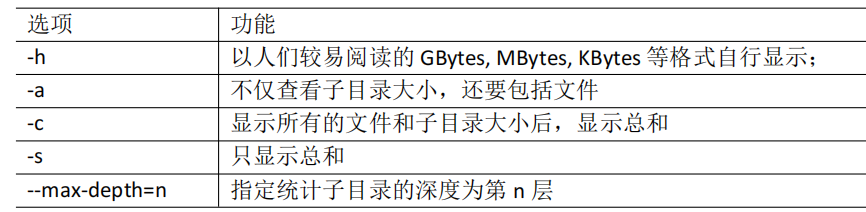
du命令
du 目录/文件 (功能描述:显示目录下每个子目录的磁盘使用情况)
1 2 [root@hadoop82 ~]# du --max-depth=1 -ah 查看目录下一级的文件的大小和总计磁盘空间大小
df查看磁盘空间使用情况
df -h转换为数据内存格式
1 2 3 df -h /目录df -h /(根目录)df -h(当前目录)
free -h当前内存使用情况
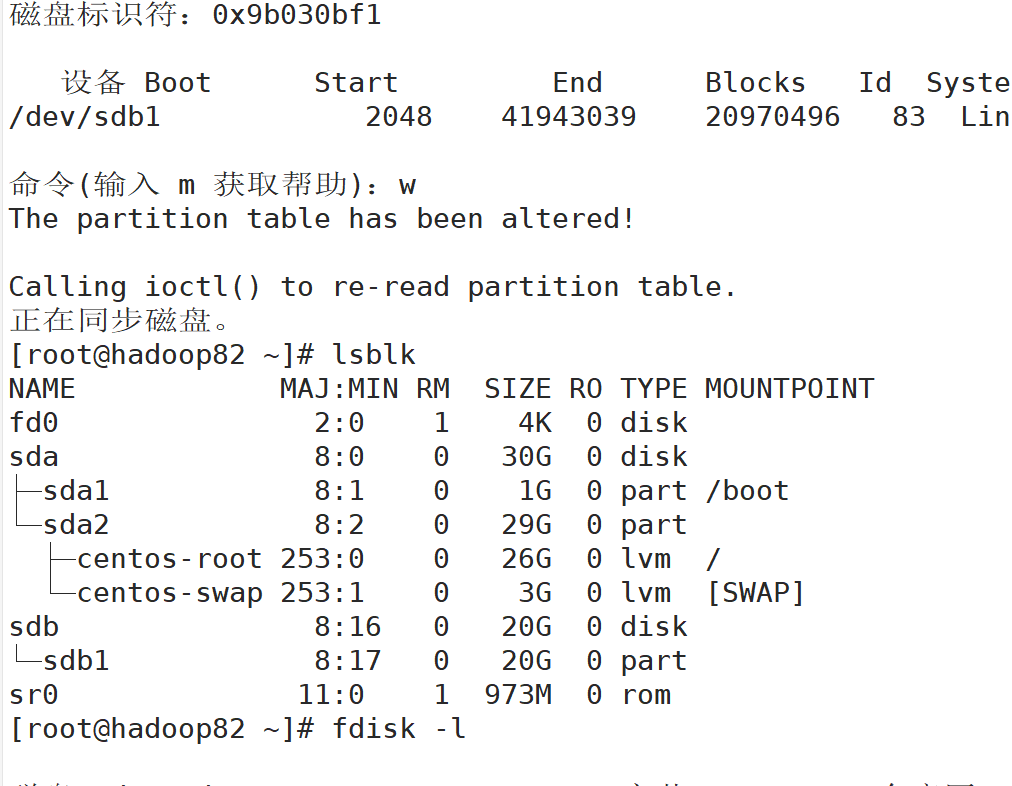
lsblk 查看设备挂载情况 (了解)
-f查看详细的设备挂载情况,显示文件系统信息
磁盘分区
fdisk分区
1 2 fdisk -l (功能描述:查看磁盘分区详情) fdisk 硬盘设备名 (功能描述:对新增硬盘进行分区操作)
要在root用户下进行
进程管理类
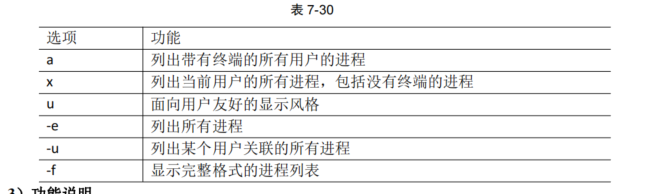
ps 查看当前系统进程状态 ps aux功能描述:查看系统中所有进程
ps -ef功能描述:可以查看子父进程之间的关系
使用时机
如果想查看进程的 CPU 占用率和内存占用率,可以使用 aux;
如果想查看进程的父进程 ID 可以使用 -ef;
终止进程
1 2 kill [选项] 进程号 (功能描述:通过进程号杀死进程) killall 进程名称 (功能描述:通过进程名称杀死进程,也支持通配符,这 在系统因负载过大而变得很慢时很有用)
kill -9强制停止 谨慎使用
(1)杀死浏览器进程
1 [root@hadoop101 桌面]# kill -9 5102
(2)通过进程名称杀死进程
1 [root@hadoop101 桌面]# killall firefox
pstree查看进程树
显示进程pid
1 [root@hadoop101 datas]# pstree -p
显示进程所属用户
1 [root@hadoop101 datas]# pstree -u
5. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
在分盘操作的时候,报错刚开始不知道什么原因,去CSDN找也没有什么先例,看尚硅谷的笔记,发现分盘只能在root用户下,自己不是root用户,因此会报错,换回root用户就正常了。
6.扩展学习部分
硬链接
http://t.csdn.cn/g8hbC来自 CSDN 解释清晰
硬链接的本质就是一条文件名和i结点的关联记录
结点就是inode
和软链接的区别:硬链接的文件指向的结点和源文件的结点是一样的,而软链接则是重新建立了一个独立的文件
当我们删除了源文件之后,发现硬链接还能正常显示原本的内容,而软链接则提示文件不存在
硬链接关联着我们的源文件,所以源文件的大小是多大,它们就是多大
但是软链接指向的是文件名,它的大小就是文件名的字节数
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天学习的Linux命令量比较多,一下子记不住这么多,比较常用的倒是都掌握了,在实操篇的内容,敲的也比较多。难度其实一般,需要掌握的都掌握了,难点都是老师说不需要死钻明白的,最后的磁盘分区,其实实现原理并不太清除,但是实现方法是知道了,就过了。没什么很大的bug,是自己疏忽大意了,忘记自己在什么用户下,权限不够导致无法分区。文件目录类这部分是重点,也是花了一上午,这部分花费的时间和精力比较多,次数敲多了,掌握起来蛮熟练的,忘记的命令可以再看下笔记。
7.9 扩展篇 Shell编程
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
3.所学内容概述
4.根据概述分章节描述
软件包管理
YUM!
1 YUM(全称为 Yellow dog Updater, Modified)是一个在 Fedora 和 RedHat 以及 CentOS 中的 Shell 前端软件包管理器。基于 RPM 包管理,能够从指定的服务器自动下载 RPM 包 并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次 次下载、安装
相当于是Linux中命令行版本的应用商店。
比如安装火狐浏览器
卸载火狐浏览器
Shell
概述
shell默认的解释器是bash
查看命令是 echo $SHELL
Shell脚本
创建一个hello.sh文件,加入内容
1 2 #!/bin/bash echo "helloworld"
执行
第一种:采用 bash 或 sh+脚本的相对路径或绝对路径(不用赋予脚本+x 权限)
第二种:采用输入脚本的绝对路径或相对路径执行脚本(必须具有可执行权限+x)
1 [root@hadoop82 ~]# chmod +x scripts/hello.sh
再执行脚本
直接输入路径
1 hello.sh /root/ script/hello.sh
变量
基本语法
(1)定义变量:变量名=变量值,注意,=号前后不能有空格
(2)撤销变量:unset 变量名
变量定义规则
1 2 3 [root@hadoop82 scripts]# my_var="hello, world" [root@hadoop82 scripts]# echo $my_var hello, world
升级成全局变量
只读(静态变量)
特殊变量
1 2 3 4 5 $n 功能描述:n 为数字,$0 代表该脚本名称,$1 -$9 代表第一到第九个参数,十以 上的参数,十以上的参数需要用大括号包含, $ $* 功能描述:这个变量代表命令行中所有的参数, $@ 功能描述:这个变量代表命令行中所有的参数, $? 功能描述:最后一次执行的命令的返回状态。如果这个变量的值为 0 ,证明上一 个命令正确执行;如果这个变量的值为非 0 (具体是哪个数,由命令自己来决定),则证明 上一个命令执行不正确了。
条件判断
语法
(1)test condition
(2)[ condition ](注意 condition 前后要有空格)
多条件判断(&& 表示前一条命令执行成功时,才执行后一条命令,|| 表示上一 条命令执行失败后,才执行下一条命令)
1 2 3 4 [atguigu@hadoop101 ~]$ [ atguigu ] && echo OK || echo notOK OK [atguigu@hadoop101 shells]$ [ ] && echo OK || echo notOK notOK
流程控制
if语句
1 2 3 4 5 6 7 8 9 if [ 条件判断式 ] then 程序 elif [ 条件判断式 ] then 程序 else 程序 fi
case 1 2 3 4 5 6 7 8 9 10 11 12 case $变量名 in "值 1" ) 如果变量的值等于值 1 ,则执行程序 1 "值 2" ) 如果变量的值等于值 2 ,则执行程序 2 …省略其他分支… *) 如果变量的值都不是以上的值,则执行此程序 esac
for循环
从1加到100
第一种
1 2 3 4 5 6 sum=0 for((i=0;i<=100;i++)) do sum=$[$sum+$i] done echo $sum
第二种
1 2 3 4 5 6 sum=0 for i in {1..100} do sum=$[$sum+$i] done echo $sum
while循环
1 2 3 4 5 6 7 8 sum=0 i=1 while [ $i -le 100 ] do sum=$[$sum+$i] i=$[$i+1] done echo $sum
read读取控制台输入
1 2 -p:指定读取值时的提示符; -t:指定读取值时等待的时间(秒)如果-t 不加表示一直等待
1 read -t 7 -p "Enter your name in 7 seconds :" NN
函数
系统函数
1 2 basename (显示文件的名称)原理就是取/的最后一位 dirname (显示文件的路径) 原理是取最后一位/的前面
自定义函数
1 2 3 4 5 6 7 8 9 10 # !/bin/bash function sum() { s=0 s=$[$1+$2] echo "$s" } read -p "请输入第一个数字: " n1; read -p "请输入第二个数字: " n2; sum $n1 $n2;
函数返回值,只能通过$?系统变量获得,可以显示加:return 返回,如果不加,将 以最后一条命令运行结果,作为返回值。return 后跟数值 n(0-255)
5.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天学习内容比较多,昨天的扩展篇收尾,软件包管理yum和一些进程管理类的再次了解。然后今天就是shell部分的学习完毕,shell在我理解有点像python,脚本语言。但是和python比,语言的简洁性,可读性都很差。毕竟是脚本语言,一些比较复杂的代码和程序,写出来就很麻烦用shell。因此现在shell是有一个let 可以用c和java的语言,还是方便的,shell今天学习就和之前的编程语言一样,变量,语法,流程和函数这些基本的。比较简单也就过掉了,在寝室学习雀氏是没有工作室学习的效率高,氛围也有差异,但是在寝室的学习今天算是满意了。
7.11 Scala基础入门
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 P1001_尚硅谷_Scala_ 课程简介 P2002_尚硅谷_Scala_Scala 概述(一)_Scala 发展历史 P3003_尚硅谷_Scala_Scala 概述(二)_Scala 和Java的关系 P4004_尚硅谷_Scala_Scala 概述(三)_Scala 特点总结 P5005_尚硅谷_Scala_Scala 环境搭建(一)_Scala 安装和交互式命令行测试 P6006_尚硅谷_Scala_Scala 环境搭建(二)_Scala 源文件编写和运行 P7007_尚硅谷_Scala_Scala 环境搭建(三)_Scala 编译结果的反编译深入分析 P8008_尚硅谷_Scala_ 在IDE中编写HelloWorld(一)_项目创建和环境配置 P9009_尚硅谷_Scala_ 在IDE中编写HelloWorld(二)_编写代码 P10010_尚硅谷_Scala_ 在IDE中编写HelloWorld(三)_代码中语法的简单说明 P11011_尚硅谷_Scala_ 在IDE中编写HelloWorld(四)_伴生对象的扩展说明 P12012_尚硅谷_Scala_ 在IDE中编写HelloWorld(五)_关联源码和查看官方指南 P13013_尚硅谷_Scala_ 变量和数据类型(一)_注释和基本编程习惯 P14014_尚硅谷_Scala_ 变量和数据类型(二)_变量和常量 P15015_尚硅谷_Scala_ 变量和数据类型(三)_标识符 P16016_尚硅谷_Scala_ 变量和数据类型(四)_字符串 P17017_尚硅谷_Scala_ 变量和数据类型(五)_控制台标准输入 P18018_尚硅谷_Scala_ 变量和数据类型(六)_读写文件 P19019_尚硅谷_Scala_ 变量和数据类型(七)_数据类型系统 P20020_尚硅谷_Scala_ 变量和数据类型(八)_整型和浮点类型 P21021_尚硅谷_Scala_ 变量和数据类型(九)_字符和布尔类型 P22022_尚硅谷_Scala_ 变量和数据类型(十)_空类型 P23023_尚硅谷_Scala_ 变量和数据类型(十一)_Unit 类型的源码实现 P24024_尚硅谷_Scala_ 变量和数据类型(十二)_类型转换(一)_Java 类型转换复习 P25025_尚硅谷_Scala_ 变量和数据类型(十二)_类型转换(三)_Scala 自动类型转换 P26026_尚硅谷_Scala_ 变量和数据类型(十二)_类型转换(四)_Scala 强制类型转换 P27027_尚硅谷_Scala_ 变量和数据类型(十二)_类型转换(五)_强转溢出面试题
3.所学内容概述
案发舒服案发分开
4.根据概述分章节描述
fff
Scala概述
因为Spark 所以要学ScalaSpark的兴起,带动Scala语言的发展!
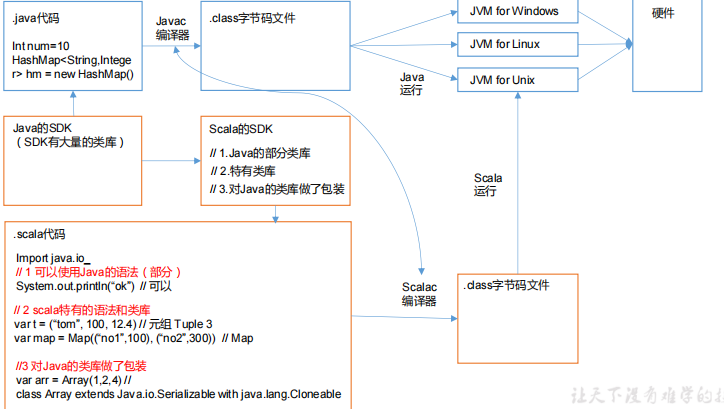
Scala基于Java,Scala和Java有密不可分的关系 关系图如下
Scala特点
Scala是一门以Java虚拟机为运行环境面向对象和函数式编程结合的静态类型的编程语言,scala跟java差不多,源代码编译成字节码文件。
我使用Scala下来,感觉Scala像是python和java的结合,很简洁,很多地方看到了python的影子。
Scala环境搭建
搭建过这么多的环境,Scala也不复杂,两三分钟就完成了。
IDEA中导入Scala稍微耗费了点时间,要引入框架。
Scala入门
Scala注解和java完全一样 /* /** 和//
变量和常量
大体和其他编程语言一样,但是要提前声明是变量还是常量
基本语法
1 2 3 4 var i:Int = 10 val j:Int = 20
注意点
1 2 3 4 5 (1 )声明变量时,类型可以省略,编译器自动推导,即类型推导 (2 )类型确定后,就不能修改,说明 Scala 是强数据类型语言。 (3 )变量声明时,必须要有初始值 (4 )在声明/定义一个变量时,可以使用 var 或者 val 来修饰,var 修饰的变量可改变, val 修饰的变量不可改。
标识符的命名规范
1 Scala 对各种变量、方法、函数等命名时使用的字符序列称为标识符。即:凡是自己可以起名字的地方都叫标识符。
1 2 3 4 和java基本差不多, (1 )以字母或者下划线开头,后接字母、数字、下划线 (2 )以操作符开头,且只包含操作符(+ - * / # !等) (3 )用反引号`....`包括的任意字符串,即使是 Scala 关键字(39 个)也可以
字符串输出
关键字println
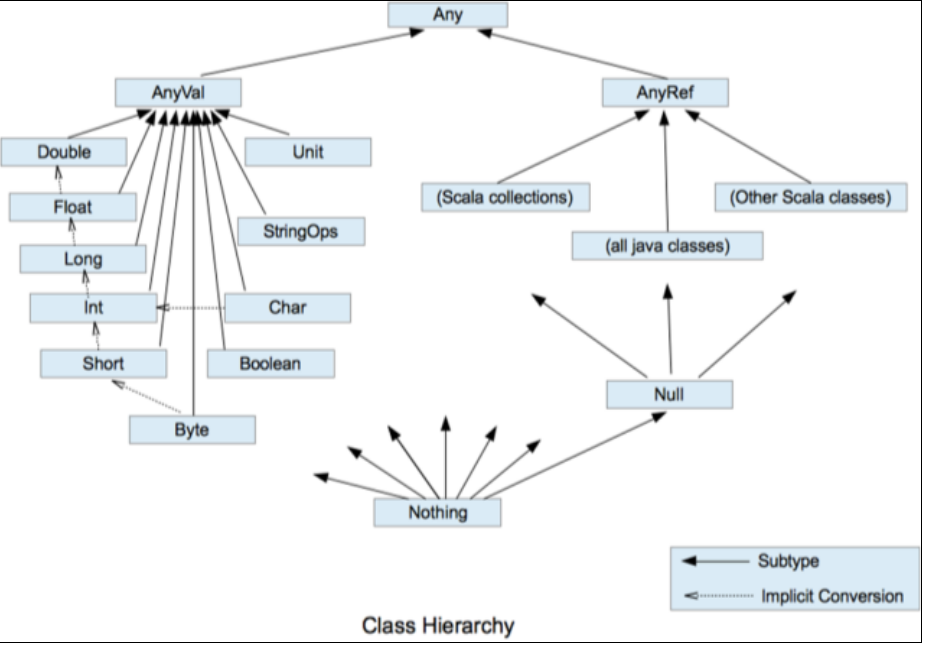
数据类型(重点) Scala一切是数据都是对象,是Any的子类 如下图
Scala两大数据类型,引用类AnyRef和数值类型的AnyVal
数值类型和其他语言大差不差,语法不一样而已
如果变量或者常量后面没有声明类型,直接等于号,不报错,是Scala自动给你匹配了对应的类型,就和python一样,还是人性化的,但是最好加上吧,可读性强一些。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 var n1:Byte = 127 var n2:Byte = -128 var n5 = 10 println(n5) var n6 = 9223372036854775807 L println(n6) var n7 = 2.2345678912 f var n8 = 2.2345678912 println("n7=" + n7) println("n8=" + n8) var c1: Char = 'a' println("c1=" + c1) var c2:Char = 'a' + 1 println(c2) println("姓名\t 年龄" ) println("西门庆\n 潘金莲" ) println("c:\\岛国\\avi" ) println("同学们都说:\"大海哥最帅\"" ) var isResult : Boolean = false var isResult2 : Boolean = true
5.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天是进入Scala的学习,Scala算是一个半新的语言,基于java的。也算是java++,一些语法和规则不太一样,基本运行原理还是差不多的,学习步骤主要是看文档,因为是语言,自己学了很多种了,前面基本的部分,大多语言都大差不差,看看文档还是比较快的,代码敲了四五个吧,关于变量的部分不是很多,今天学习的任务也不是很重,顺便把前几天的centOS中的命令,在ubuntu中,又使用了一些,ubuntu安装是用apt的,不是用Centos的yum,ubuntu下了一个java。
7.13 hadoop基础入门
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 01 _尚硅谷_课程简介_大数据课程02 _尚硅谷_课程简介_Hadoop 课程03 _尚硅谷_入门_大数据概念04 _尚硅谷_入门_大数据特点(4 V)05 _尚硅谷_入门_大数据应用场景06 _尚硅谷_入门_大数据发展前景07 _尚硅谷_入门_大数据部门业务流程分析08 _尚硅谷_入门_大数据部门组织结构(重点)09 _尚硅谷_Hadoop_ 是什么10 _尚硅谷_Hadoop_ 发展历史11 _尚硅谷_Hadoop_ 三大发行版本12 _尚硅谷_Hadoop_ 优势(4 高)13 _尚硅谷_Hadoop_1 .x和2 .x区别14 _尚硅谷_Hadoop_ 组成15 _尚硅谷_Hadoop_ 大数据技术生态体系16 _尚硅谷_Hadoop_ 推荐系统框架图17 _尚硅谷_环境搭建_虚拟机准备18 _尚硅谷_环境搭建_JDK 安装19 _尚硅谷_环境搭建_Hadoop 安装20 _尚硅谷_环境搭建_Hadoop 目录结构21 _尚硅谷_环境搭建_Hadoop 官网手册22 _尚硅谷_本地模式_Grep 官方案例23 _尚硅谷_本地模式_WordCount 官方案例24 _尚硅谷_伪分布式_启动HDFS并运行MR程序25 _尚硅谷_伪分布式_Log 日志查看和NN格式化前强调26 _尚硅谷_伪分布式_NameNode 格式化注意事项27 _尚硅谷_伪分布式_启动YARN并运行MR程序28 _尚硅谷_伪分布式_配置历史服务器29 _尚硅谷_伪分布式_配置日志聚集30 _尚硅谷_伪分布式_配置文件说明
3.所学内容概述
大数据入门
hadoop概述入门
环境搭建
本地模式
伪分布式
4.根据概述分章节描述
hadoop概述
hadoop是一个分布式的基础架构,用于存储和分析计算数据,解决数据问题。
hadoop的组成
MapReduce和HDFS是重点
虚拟机环境搭建准备 1 2 3 4 5 6 7 1. 克隆虚拟机 2. 修改克隆虚拟机的静态IP3. 修改主机名4. 关闭防火墙5. 创建atguigu用户6. 配置atguigu用户具有root权限安装JDK 和 hadoop
安装Jdk和Hadoop时候注意路径,配好环境变量,需要检查。
java -version和hadoop可以检查环境变量有没有配置好
hadoop目录结构
1 2 3 4 5 (1 )bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本 2 )etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件(3 )lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能) (4 )sbin目录:存放启动或停止Hadoop相关服务的脚本 5 )share目录:存放Hadoop的依赖jar包、文档、和官方案例
Hadoop运行模式
本地运行
执行命令
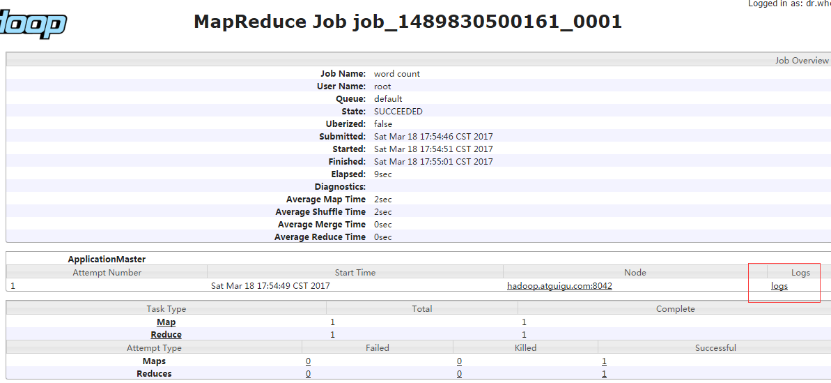
1 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
伪分布式运行模式
具体配置以及测试命令见 文档
配置集群文档一定要注意命令以及主机名
1 2 3 (1 )配置集群 (2 )启动、测试集群增、删、查 (3 )执行WordCount 案例
查看集群启动成功用jps
MapReduce和YARN大同小异
配置历史服务器 日志聚集
步骤都是配置yarn-site.xml文件然后添加配置
启动集群 执行即可
运行情况
6.扩展学习部分
说下这一星期操作linux系统出现的一些常见问题吧,最常见的就是路径问题,经常cd或者解压包的时候,vim和cat找不到文件,大多数就是自己路径的问题。自己出现了的一次问题:我在hadoop-2.7.1中有个文件名叫etc,但是在Linux中根目录也有一个文件名叫etc,所以有好几次,cd和调用命令的时候,报错,说找不到路径,闲下来的时候去CSDN搜了一下,路径的问题,单独一个/代表跟根目录,像/etc/hadoop就是进入根目录的etc中的hadoop目录,如果etc/hadoop就是当前目录有个文件叫etc,是相对的路径,而etc中的hadoop前面带/就是绝对路径,算是两种路径结合在一起,导致自己好几次不成功,几次的经验就是换一个新的路径的时候,ll看一下路径的文件,防止解压等操作的时候,造成不必要的麻烦。
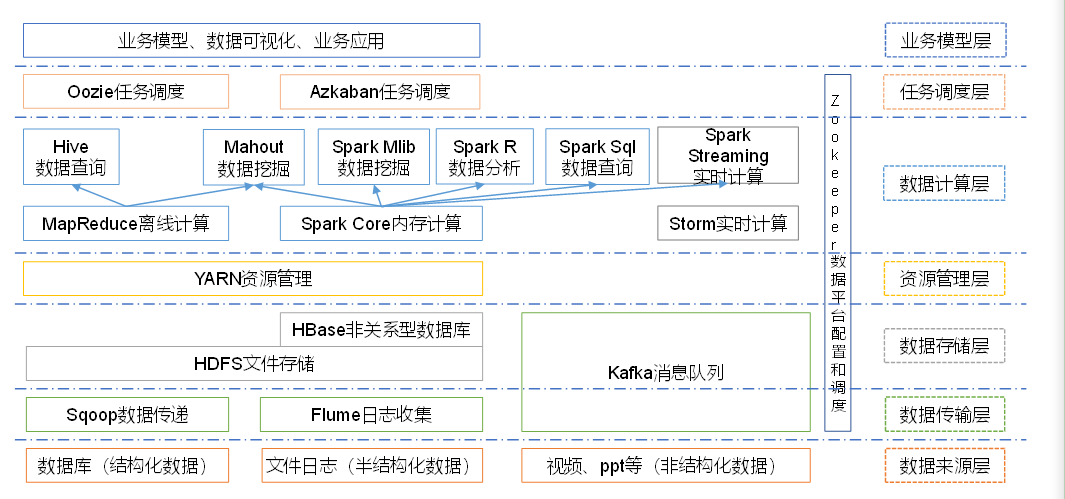
大数据的技术生态系统体系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 )Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。2 )Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。3 )Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:(1 )通过O(1 )的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB 的消息存储也能够保持长时间的稳定性能。 (2 )高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。 (3 )支持通过Kafka服务器和消费机集群来分区消息。 (4 )支持Hadoop并行数据加载。 4 )Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。5 )Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。6 )Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。7 )Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。8 )Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。10 )R 语言:R 是用于统计分析、绘图的语言和操作环境。R 是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。11 )Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。12 )ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天从Scala又来看hadoop了,hadoop的概念性不是很好理解,在我看来hadoop是一个框架,而且是开源的。相当于一个思想,它有提供模块和软件做支撑,是大数据必学的东西。今天的内容有点难度,代码会敲,但是内容和代码实现的原因,不是很理解透彻,今天配置java和hadoop的时候,路径出现了一些问题,学习内容也是偏概念性的,hadoop的目录结构作用等,一些命令已经熟悉了,伪分布式运行这里问题有点大,不理解这样做的原理和原因。
7.14 hadoop完全分布式
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 31 _ 尚硅谷_ 完全分布式_ 虚拟机环境准备32 _ 尚硅谷_ 完全分布式_scp案例33 _ 尚硅谷_ 完全分布式_rsync案例34 _ 尚硅谷_ 完全分布式_ 集群分发脚本xsync35 _ 尚硅谷_ 完全分布式_ 集群配置36 _ 尚硅谷_ 完全分布式_ 集群单节点启动37 _ 尚硅谷_ 完全分布式_ 集群ssh配置38 _ 尚硅谷_ 完全分布式_ 集群群起39 _ 尚硅谷_ 完全分布式_ 集群文件存储路径说明40 _ 尚硅谷_ 完全分布式_ 集群启动停止方式总结41 _ 尚硅谷_ 每日回顾42 _ 尚硅谷_ 完全分布式_RM启动注意事项43 _ 尚硅谷_ 完全分布式_Crondtab定时任务调度44 _ 尚硅谷_ 完全分布式_ 集群时间同步
3.所学内容概述
准备虚拟机克隆
编写集群分发脚本
集群配置
4.根据概述分章节描述.
准备虚拟机克隆
虚拟机克隆回来需要进行ip配置,看那个老师克隆步骤和自己的对不上,文件都不一样,自己是对着实验指导书配的。查了资料,总结了自己的步骤,后面也是全部对的上的都成功的。
1 2 3 4 5 6 7 配置ip [root@localhost ~] systemctl restart network systemctl restart NetworkManager 虚拟机的网络配置就如上
编写集群分发配置
克隆机的配置和原来是一样的,明显是不妥当的,一个一个改又很麻烦,就需要集群分发。用xsync
xsync集群分发脚本
在/usr/sjh/bin这个目录下存放的脚本,sjh用户可以在系统任何地方直接执行。
(a)在/home/atguigu目录下创建bin目录,并在bin目录下xsync创建文件,文件内容如下:
原来的教程是在/home/sjh目录 试了不行 改到了/usr/sjh 就好了
1 2 3 4 [root@hadoop83 ~]$ mkdir bin [root@hadoop83 ~]$ cd bin/ [root@hadoop83 bin]$ touch xsync [root@hadoop83 bin]$ vi xsync
写入xsync
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 pcount=$ if ((pcount==0 )); thenecho no args; exit; fi p1=$1 fname=`basename $p1` echo fname=$fname pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir user=`whoami` for ((host=103 ; host<105 ; host++)); doecho ------------------- hadoop$host -------------- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done
修改脚本的权限 主要是添加执行权限 以及各用户能调用
1 [sjh@hadoop83 bin]# chmod 777 xsync
修改脚本形式
1 [sjh@hadoop83 bin]# xsync /usr/sjh/bin
集群配置
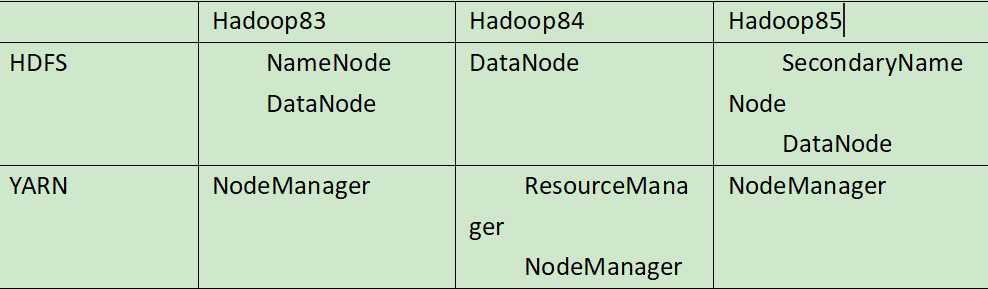
部署规划
以下配置文件直接copy尚硅谷的 自己的集群搭建 注意自己路径和文件名
核心配置文件
配置core-site.xml
1 [atguigu@hadoop102 hadoop]$ vi core-site.xml
在该文件中编写如下配置
1 2 3 4 5 6 7 8 9 10 <property > <name > fs.defaultFS</name > <value > hdfs://hadoop102:9000</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /opt/module/hadoop-2.7.2/data/tmp</value > </property >
HDFS配置文件
配置hadoop-env.sh
1 2 [atguigu@hadoop102 hadoop]$ vi hadoop-env.sh export JAVA_HOME =/opt/module/jdk1.8.0_144
配置hdfs-site.xml
1 [atguigu@hadoop102 hadoop]$ vi hdfs-site.xml
配置如下
1 2 3 4 5 6 7 8 9 <property > <name > dfs.replication</name > <value > 3</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > hadoop104:50090</value > </property >
YARN配置
配置yarn-env.sh
1 2 [atguigu@hadoop102 hadoop]$ vi yarn-env.sh export JAVA_HOME =/opt/module/jdk1.8.0_144
配置yarn-site.xml
1 [atguigu@hadoop102 hadoop]$ vi yarn-site.xml
配置如下
1 2 3 4 5 6 7 8 9 10 <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > hadoop103</value > </property >
MapReduce配置文件
配置mapred-env.sh
1 2 [atguigu@hadoop102 hadoop]$ vi mapred-env.sh export JAVA_HOME =/opt/module/jdk1.8.0_144
配置mapred-site.xml
1 2 [atguigu@hadoop102 hadoop] $ cp mapred-site.xml .template mapred-site.xml [atguigu@hadoop102 hadoop] $ vi mapred-site.xml
在该文件中增加如下配置
1 2 3 4 5 <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property >
在集群上分发配置好的Hadoop配置文件
1 [atguigu@hadoop102 hadoop]$ xsync /opt/m odule/hadoop-2.7.2/
分发完毕 去克隆机查看分发配置情况
集群单点启动
这个很常规,之前的笔记有
每次都一个一个节点启动,如果节点数增加到1000个怎么办。所以要学一起启动利用集群 群起
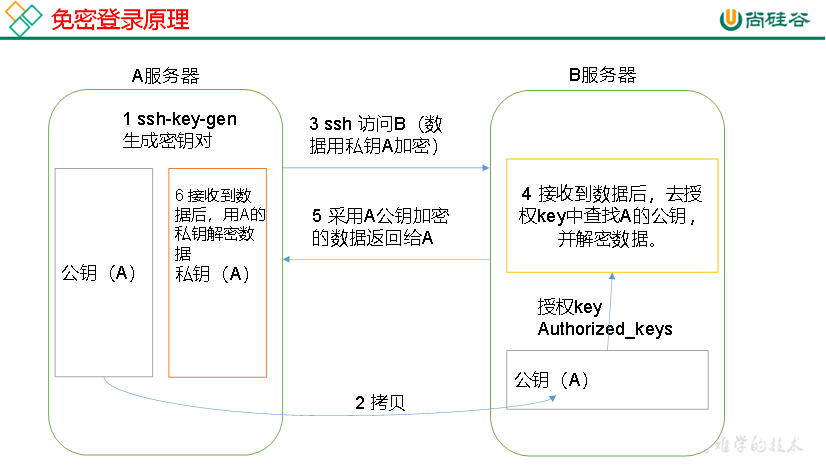
首先要解决SSH无密登陆配置 不然每次群起要输入很多次密码
SSh无密登录配置
进入另外一台电脑 ssh语法
无密钥登录原理
第一步生成公钥和私钥:
1 [atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
在/root/.ssh会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
拷贝到免密的机器上 自身也需要
1 2 3 [atguigu@hadoop102 .ssh]$ ssh-copy -id hadoop102 [atguigu@hadoop102 .ssh]$ ssh-copy -id hadoop103 [atguigu@hadoop102 .ssh]$ ssh-copy -id hadoop104
.ssh文件夹文件功能解释
1 2 3 4 known_hosts 记录ssh访问过计算机的公钥(public key ) id_rsa 生成的私钥 id_rsa.pub 生成的公钥 authorized_keys 存放授权过得无密登录服务器公钥
群起集群
配置Slaves
1 2 /opt/m odule/hadoop-2.7.2/ etc/hadoop/ slaves[atguigu@hadoop102 hadoop]$ vi slaves
该文件增加内容
1 2 3 hadoop83 hadoop84 hadoop85
同步所有节点配置文件
1 [atguigu@hadoop102 hadoop]$ xsync slaves
启动集群
在hadoop83中 放集群的克隆机
格式化
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ bin/hdfs namenode -format
启动HDFS
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ sbin/start-dfs.sh
启动YARN
1 [atguigu@hadoop103 hadoop-2.7 .2 ]$ sbin/start-yarn.sh
集群基本测试
1 2 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hdfs dfs -mkdir -p /user/ atguigu/input [atguigu@hadoop102 hadoop-2.7 .2 ]$ hdfs dfs -put wcinput/wc.input /u ser/atguigu/i nput
上传大文件
1 2 [atguigu@hadoop102 hadoop-2.7 .2 ]$ bin/hadoop fs -put /opt/ software/hadoop-2.7.2.tar.gz /u ser/atguigu/i nput
查看磁盘存储文件内容
1 2 3 4 5 [atguigu@hadoop102 subdir0]$ cat blk_1073741825 hadoop yarn hadoop mapreduce atguigu atguigu
集群启动/停止方式总结
1 2 3 4 (1 )分别启动/停止HDFS组件 hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode (2 )启动/停止YARN yarn-daemon.sh start / stop resourcemanager / nodemanager
集群时间同步
检查ntp是否安装
1 [root@hadoop102 桌面]# rpm -qa|grep ntp
其他机器配置(必须root)
1 [root@hadoop103 桌面]# crontab -e
修改文件时间 Linux中有,指每十分钟切换一次
5. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
克隆机的时候,因为路径和老师不一样,代码打出来,老师有的文件打开是有的,但是我打开是没的,但是最终目标都是连接配置静态ip地址,和能正常上网,自己找linux尚硅谷的资料,看着配置的,方法很不一样,目的是正常达成了,详情在笔记 虚拟机环境准备有。
还有个报错的问题。就是在执行ssh命令的时候,提示lias cman='man -M /usr//share/man/zh_CN’报错,看提示信息是在etc/profile.d/cman.sh这个文件下的问题,ssh我使用的时候是正常的,但是会报出这个错误,百度找了,然后进该文件比对,发现最前面少个a然后路径//中间少了local。加上以后ssh就没报错信息了,好像是自己最开始安装中文语言包的时候复制进去的时候光标的原因吧,不太清楚。
6.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的学习内容不是很多,但是有一定的难度,和小问题比较多,但都解决了。问题不大,集群的配置比较麻烦,但是单机开启和昨天的命令是一样的。无非是配置多集群的时候,稍微麻烦了点,而且配置文件和老师差异比较大,源被克隆的机子和老师配置很多不一样,克隆出来的机子很多都是要自己去搜命令。好在顺利启动RM了。也能正常使。还是偏向概念性多点,理解集群运行的原理,代码就那么来回几条,多敲几遍就OK了,文件也是配置一次以后,用集群配置就方便了很多。
7.16 HDFS
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 70 _尚硅谷_HDFS_ 机架感知-副本存储节点选择P71 71 _尚硅谷_HDFS_ 读数据流程(面试重点) 72 _尚硅谷_HDFS_NN 和2 NN工作机制(面试重点)73 _尚硅谷_HDFS_Fsimage 和Edits解析74 _尚硅谷_HDFS_CheckPoint 时间设置75 _尚硅谷_HDFS_NN 故障处理_案例76 _尚硅谷_HDFS_ 安全模式77 _尚硅谷_HDFS_ 集群安全模式_案例78 _尚硅谷_HDFS_NN 多目录配置_案例79 _尚硅谷_每日回顾80 _尚硅谷_HDFS_DN 工作机制(面试重点)81 _尚硅谷_HDFS_ 数据完整性82 _尚硅谷_HDFS_ 掉线时限参数设置83 _尚硅谷_HDFS_ 服役新节点_案例84 _尚硅谷_HDFS_ 添加白名单_案例85 _尚硅谷_HDFS_ 黑名单退役_案例86 _尚硅谷_HDFS_DN 多目录配置_案例87 _尚硅谷_HDFS 新特性_集群间数据拷贝88 _尚硅谷_HDFS 新特性_小文件归档案例89 _尚硅谷_HDFS 新特性_回收站案例90 _尚硅谷_HDFS 新特性_快照管理
3.所学内容概述
HDFS概述
HDFS的shell操作
HDFS客户端环境准备
HDFS的API操作
HDFS的I/O流操作
4.根据概述分章节描述
HDFS概述
HDFS是分布式文件管理系统的一种。
优点
高容错 数据自动保存多个副本 副本丢失以后可以自动恢复
适合处理大数据
数据规模 能处理数据规模达到GB TB 甚至PB的数据
文件规模:能处理百万规模以上的文件数量,数量相当之大
可以构建在廉价机器上
通过多副本机制,提高可靠性
缺点
不适合低延迟数据访问,毫秒这种数据存储,做不到
对小文件存储,不够高效
仅仅支持数据追加append 不支持修改
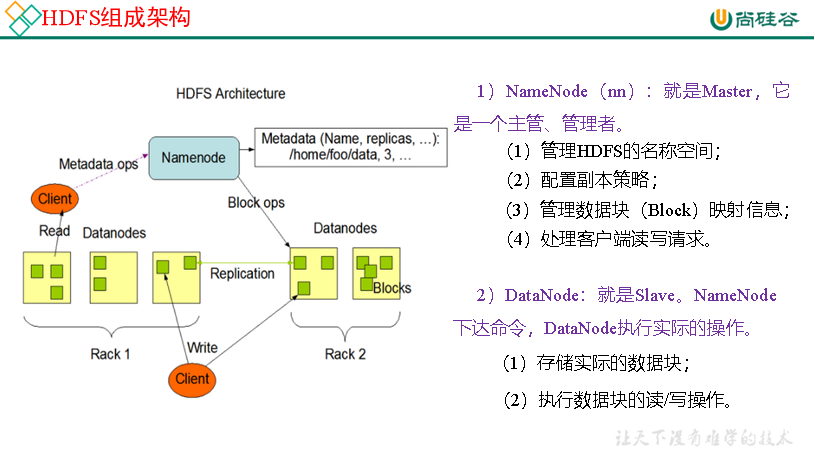
HDFS组成架构
分为4个方面 NameNode DataNode Client客户端 和 Secondary NameNode
Secondary NameNode辅助NameNode,可以定期合并Edits和Fsming,必要的时候可以辅助恢复NameNode,提高安全性。
HDFS的Shell操作(开发重点)
基本语法
1 2 3 bin /hadoop fs - 具体命令bin /hdfs dfs 具体命令
查看命令大全
基本常用命令合集
(0)启动Hadoop集群(方便后续的测试)
1 2 [atguigu@hadoop102 hadoop-2.7 .2 ]$ sbin/start-dfs.sh [atguigu@hadoop103 hadoop-2.7 .2 ]$ sbin/start-yarn.sh
(1)-help:输出这个命令参数
1 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -help rm
(2)-ls: 显示目录信息
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -ls /
( 3 )-mkdir:在HDFS上创建目录
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -mkdir -p /sanguo/ shuguo
(4)-moveFromLocal:从本地剪切粘贴到HDFS
1 2 [atguigu@hadoop102 hadoop-2.7 .2 ]$ touch kongming.txt [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
(5)-appendToFile:追加一个文件到已经存在的文件末尾
1 2 3 4 5 [atguigu@hadoop102 hadoop-2.7 .2 ]$ touch liubei.txt [atguigu@hadoop102 hadoop-2.7 .2 ]$ vi liubei.txt 输入 san gu mao lu [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
(6)-cat:显示文件内容
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -cat /sanguo/ shuguo/kongming.txt
(7)-chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
1 2 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -chmod 666 /sanguo/ shuguo/kongming.txt [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -chown atguigu:atguigu /sanguo/ shuguo/kongming.txt
(8)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -copyFromLocal README.txt /
(9)-copyToLocal:从HDFS拷贝到本地
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -copyToLocal /sanguo/ shuguo/kongming.txt ./
(10)-cp :从HDFS的一个路径拷贝到HDFS的另一个路径
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -cp /sanguo/ shuguo/kongming.txt / zhuge.txt
(11)-mv:在HDFS目录中移动文件
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -mv /zhuge.txt / sanguo/shuguo/
(12)-get:等同于copyToLocal,就是从HDFS下载文件到本地
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -get /sanguo/ shuguo/kongming.txt ./
(13)-getmerge:合并下载多个文件
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -getmerge /user/ atguigu/test/ * ./zaiyiqi.txt
(14)-put:等同于copyFromLocal
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -put ./zaiyiqi.txt /u ser/atguigu/ test/
(15)-tail:显示一个文件的末尾
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -tail /sanguo/ shuguo/kongming.txt
(16)-rm:删除文件或文件夹
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -rm /user/ atguigu/test/ jinlian2.txt
(17)-rmdir:删除空目录
1 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -rmdir /test
(18)-du统计文件夹的大小信息
1 2 3 4 5 6 7 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -du -s -h /user/ atguigu/test 2.7 K /user/ atguigu/test[atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -du -h /user/ atguigu/test 1.3 K /user/ atguigu/test/ README.txt15 /user/ atguigu/test/ jinlian.txt1.4 K /user/ atguigu/test/ zaiyiqi.txt
(19)-setrep:设置HDFS中文件的副本数量
1 [atguigu@hadoop102 hadoop-2.7 .2 ]$ hadoop fs -setrep 10 /sanguo/ shuguo/kongming.txt
HDFS客户端环境准备
因为教学老师版本那不一样,也没有下载资料,所以环境什么都是自己搜的。
解压hadoop2.7.1的linux安装包在,windows系统中,然后在CSDN搜到了两个文件,覆盖在hadoop中的bin目录中。两个文件有链接的。然后配置环境变量
%HADOOP_HOME%指定bin目录
path中 %HADOOP_HOME%\bin
http://t.csdn.cn/W0kBg 来自CSDN中
HDFS的API操作
参数优先级
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的默认配置
文件下载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Test public void testCopyToLocalFile () throws IOException, InterruptedException, URISyntaxException{ Configuration configuration = new Configuration (); FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop102:9000" ), configuration, "atguigu" ); fs.copyToLocalFile(false , new Path ("/banzhang.txt" ), new Path ("e:/banhua.txt" ), true ); fs.close(); }
HDFS文件删除
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void testDelete () throws IOException, InterruptedException, URISyntaxException{ Configuration configuration = new Configuration (); FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop102:9000" ), configuration, "atguigu" ); fs.delete(new Path ("/0508/" ), true ); fs.close(); }
HDFS文件名更改
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void testRename () throws IOException, InterruptedException, URISyntaxException{ Configuration configuration = new Configuration (); FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop102:9000" ), configuration, "atguigu" ); fs.rename(new Path ("/banzhang.txt" ), new Path ("/banhua.txt" )); fs.close(); }
HDFS文件详情查看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @Test public void testListFiles () throws IOException, InterruptedException, URISyntaxException{ Configuration configuration = new Configuration (); FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop102:9000" ), configuration, "atguigu" ); RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path ("/" ), true ); while (listFiles.hasNext()){ LocatedFileStatus status = listFiles.next(); System.out.println(status.getPath().getName()); System.out.println(status.getLen()); System.out.println(status.getPermission()); System.out.println(status.getGroup()); BlockLocation[] blockLocations = status.getBlockLocations(); for (BlockLocation blockLocation : blockLocations) { String[] hosts = blockLocation.getHosts(); for (String host : hosts) { System.out.println(host); } } System.out.println("-----------班长的分割线----------" ); } fs.close(); }
文件和文件夹判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Test public void testListStatus () throws IOException, InterruptedException, URISyntaxException{ Configuration configuration = new Configuration (); FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop83:9000" ), configuration, "root" ); FileStatus[] listStatus = fs.listStatus(new Path ("/" )); for (FileStatus fileStatus : listStatus) { if (fileStatus.isFile()) { System.out.println("文件:" +fileStatus.getPath().getName()); }else { System.out.println("文件名:" +fileStatus.getPath().getName()); } } fs.close(); }
HDFS的I/O流操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Test public void putFileToHDFS () throws URISyntaxException, IOException, InterruptedException { Configuration configuration = new Configuration (); FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop83:9000" ), configuration, "root" ); FileInputStream fis = new FileInputStream ("E:/banhua.txt" ); FSDataOutputStream fos = fs.create(new Path ("/banzhang.txt" )); IOUtils.copyBytes(fis,fos,configuration); IOUtils.closeStream(fis); IOUtils.closeStream(fos); fs.close(); }
文件下载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void getFileFromHDFS () throws URISyntaxException, IOException, InterruptedException { Configuration configuration = new Configuration (); FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop83:9000" ), configuration, "root" ); FSDataInputStream fis = fs.open(new Path ("/banhua.txt" )); FileOutputStream fos = new FileOutputStream ("e:/HDFS-banhua.txt" ); IOUtils.copyBytes(fis,fos,configuration); IOUtils.closeStream(fis); IOUtils.closeStream(fos); fs.close(); }
定位文件读取
分两步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 @Test public void readFileSeek1 () throws IOException, InterruptedException, URISyntaxException{ Configuration configuration = new Configuration (); FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop83:9000" ), configuration, "root" ); FSDataInputStream fis = fs.open(new Path ("/hadoop-2.7.1.tar.gz" )); FileOutputStream fos = new FileOutputStream ("e:/hadoop-2.7.1.tar.gz.part1" ); byte [] buf = new byte [1024 ]; for (int i = 0 ; i < 1024 * 128 ; i++){ fis.read(buf); fos.write(buf); } IOUtils.closeStream(fis); IOUtils.closeStream(fos); fs.close(); } @Test public void readFileSeek2 () throws IOException, InterruptedException, URISyntaxException{ Configuration configuration = new Configuration (); FileSystem fs = FileSystem.get(new URI ("hdfs://hadoop83:9000" ), configuration, "root" ); FSDataInputStream fis = fs.open(new Path ("/hadoop-2.7.1.tar.gz" )); fis.seek(1024 *1024 *128 ); FileOutputStream fos = new FileOutputStream ("e:/hadoop-2.7.1.tar.gz.part2" ); IOUtils.copyBytes(fis, fos, configuration); IOUtils.closeStream(fis); IOUtils.closeStream(fos); }
5. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
是这样报错的,也看不太懂,大致意思就是找不到,文件的权限,之类的话,去CSDN看别人写的,突然发现有人在get最后面是写的root,想到自己一直都是以root用户登陆,就把用户sjh改成了root,就好了。
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的学习内容的重点在于掌握Java来充当客户端,利用HDFS来做上传数据或者从hadoop下载数据。这次的内容就偏向代码的敲写了,每次操作自己都去敲了一遍,看完视频自己去敲过来的,难度一般,因为对代码的处理比较多,自己对代码比较敏感,学习起来上手也快。比较麻烦的地方是windows配置环境,和IDEA配置客户端的环境准备。配置了一个小时左右,找压缩包,和pox文件花费了很多时间,中间也出现了一些小问题,但是都解决了。学习状态还不错,优于大量的概念问题的章节。
7.18 Scala函数式编程 面向对象
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 057 _尚硅谷_Scala_ 函数式编程(三)_函数高级(二)_高阶函数(三)_函数作为返回值058 _尚硅谷_Scala_ 函数式编程(三)_函数高级(二)_高阶函数(四)_应用案例059 _尚硅谷_Scala_ 函数式编程(三)_函数高级(三)_扩展练习(一)_匿名函数060 _尚硅谷_Scala_ 函数式编程(三)_函数高级(三)_扩展练习(二)_函数作为返回值061 _尚硅谷_Scala_ 函数式编程(三)_函数高级(四)_闭包(一)_概念和原理062 _尚硅谷_Scala_ 函数式编程(三)_函数高级(四)_闭包(二)_具体应用063 _尚硅谷_Scala_ 函数式编程(三)_函数高级(四)_柯里化064 _尚硅谷_Scala_ 函数式编程(三)_函数高级(五)_递归(一)_概念和实现065 _尚硅谷_Scala_ 函数式编程(三)_函数高级(五)_递归(二)_尾递归优066 _尚硅谷_Scala_ 函数式编程(三)_函数高级(六)_控制抽象(一)参数067 _尚硅谷_Scala_ 函数式编程(三)_函数高级(六)_控制抽象(二)_传名参数068 _尚硅谷_Scala_ 函数式编程(三)_函数高级(六)_控制抽象(三)_自定义While 循环069 _尚硅谷_Scala_ 函数式编程(三)_函数高级(七)_惰性加载070 _尚硅谷_Scala_ 面向对象(一)_包(一)_声明和访问071 _尚硅谷_Scala_ 面向对象(一)_包(二)_包对象072 _尚硅谷_Scala_ 面向对象(一)_包(三)_导包说明073 _尚硅谷_Scala_ 面向对象(二)_类和对象074 _尚硅谷_Scala_ 面向对象(三)_封装(一)_访问权限075 _尚硅谷_Scala_ 面向对象(三)_封装(二)_构造器076 _尚硅谷_Scala_ 面向对象(三)_封装(三)_构造器参数077 _尚硅谷_Scala_ 面向对象(四)_继承078 _尚硅谷_Scala_ 面向对象(五)_多态080 _尚硅谷_Scala_ 面向对象(六)_抽象类(二)_匿名子类082 _尚硅谷_Scala_ 面向对象(七)_伴生对象(二)_单例设计模式084 _尚硅谷_Scala_ 面向对象(八)_特质(二)_特质的混入085 _尚硅谷_Scala_ 面向对象(八)_特质(三)_特质的叠加087 _尚硅谷_Scala_ 面向对象(八)_特质(五)_特质和抽象类的区别088 _尚硅谷_Scala_ 面向对象(八)_特质(六)_自身类型089 _尚硅谷_Scala_ 面向对象(九)_扩展内容(一)_类型检测和转换090 _尚硅谷_Scala_ 面向对象(九)_扩展内容(二)_枚举类和应用类
3.所学内容概述
函数基础
函数高级
4.根据概述分章节描述
函数基础
面向对象编程和函数式编程的区别
面向对象编程:解决问题,分解对象,属性,行为,然后通过对象的关系以及行为的调用来解决问题。
Scala语言是一个完全面向对象编程语言。万物皆对象,比Java还有过之。对象的本质就是对数据和行为的封装
函数式编程:将问题分解成步骤,将步骤封装,调用封装好的步骤解决问题
Scala 语言是一个完全函数式编程语言。万物皆函数。函数的本质:函数可以当做一个值进行传递
自己的使用体验来讲,Scala运行速度和python差不多,比Java慢了很多,Scala编译很慢,效率不高,可能函数式编程运行速度都很慢吧
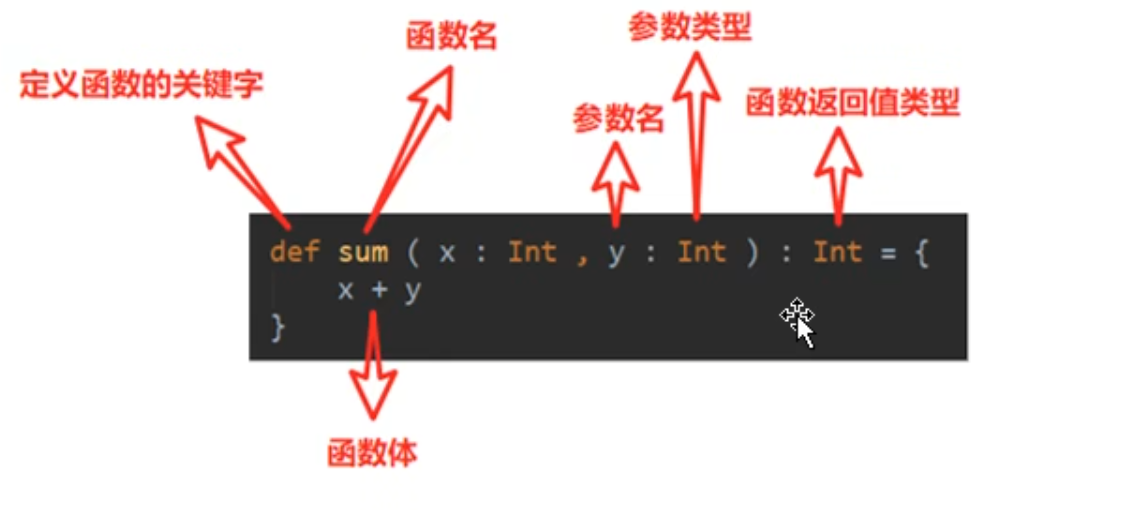
函数基本语法
在main里面的是函数,在main外面的是方法
1 2 3 4 5 def printTest String ) : String = { println("hi" +x) x }
Scala函数参数和返回值的几种情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def main Array [String ]): Unit = { def test1 Unit ={ println("无参,无返回值" ) } println(test1()) def test2 String ={ "无参,有返回值" } println(test2()) def test3 String ):Unit ={ println(s) } test3("jingling" ) def test4 String ):String ={ s+"有参,有返回值" } println(test4("hello " )) def test5 String , age:Int ):Unit ={ println(s"我叫${name} , 我的年龄是${age} 岁" ) } println(test5("dealing" ,40 )) }
函数的特殊情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def main Array [String ]): Unit = { def test String * ): Unit = { println(s) } test("Hello" , "Scala" ) test() def test2 String , s: String * ): Unit = { println(name + "," + s) } test2("jinlian" , "dalang" ) def test3 String , age : Int = 30 ): Unit = { println(s"$name , $age " ) } test3("jinlian" , 20 ) test3("dalang" ) def test4 String = "男" , name : String ): Unit = { println(s"$name , $sex " ) } test4(name="ximenqing" ) }
Scala代码的简化
能简则简,可读性会差很多!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def main Array [String ]): Unit = { def f String ): String = { return s + " jinlian" } println(f("Hello" )) def f1 String ): String = { s + " jinlian" } println(f1("Hello" )) def f2 String ):String = s + " jinlian" def f3 String ) = s + " jinlian" println(f3("Hello3" )) def f4 String = { return "ximenqing4" } println(f4()) def f5 Unit = { return "dalang5" } println(f5()) def f6 "dalang6" } println(f6()) def f7 "dalang7" println(f7()) println(f7) def f8 "dalang" println(f8) def f9 String )=>{println("wusong" )} def f10 String =>Unit ) = { f("" ) } f10(f9) println(f10((x:String )=>{println("wusong" )})) }
函数高级
函数的高阶用法 我认为可读性极差极差!
函数作为值传递
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 val f = foo println(f) val f1 = foo _ foo() f1() var f2:()=>Int = foo def foo Int = { println("foo..." ) 1 }
函数也可以作为函数传递
1 2 3 4 5 6 7 8 9 10 11 12 def f1 Int , Int ) => Int ): Int = { f(2 , 4 ) } def add Int , b: Int ): Int = a + b println(f1(add)) println(f1(add _))
函数可以作为函数的返回值返回
1 2 3 4 5 6 7 8 9 10 11 def f1 def f2 } f2 _ } val f = f1()f() f1()()
匿名函数
语法说明
1 2 (x:Int ) => {println{"...." }} x:表示输入参数类型;Int :表示输入参数类型;函数体:表示具体代码逻辑
匿名函数也可以至简
1 2 3 (1 )参数的类型可以省略,会根据形参进行自动的推导 (2 )类型省略之后,发现只有一个参数,则圆括号可以省略;其他情况:没有参数和参数超过 1 的永远不能省略圆括号。 (3 )匿名函数如果只有一行,则大括号也可以省略 (4 )如果参数只出现一次,则参数省略且后面参数可以用_ 代替
代码实现 简化一个形参匿名函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def main Array [String ]): Unit = { def operation Array [Int ], op: Int => Int ) = { for (elem <- arr) yield op(elem) } def op Int ): Int = { ele + 1 } val arr = operation(Array (1 , 2 , 3 , 4 ), op) println(arr.mkString("," )) val arr1 = operation(Array (1 , 2 , 3 , 4 ), (ele: Int ) => { ele + 1 }) println(arr1.mkString("," )) val arr2 = operation(Array (1 , 2 , 3 , 4 ), (ele) => { ele + 1 }) println(arr2.mkString("," )) val arr3 = operation(Array (1 , 2 , 3 , 4 ), ele => { ele + 1 }) println(arr3.mkString("," )) val arr4 = operation(Array (1 , 2 , 3 , 4 ), ele => ele + 1 ) println(arr4.mkString("," )) val arr5 = operation(Array (1 , 2 , 3 , 4 ), _ + 1 ) println(arr5.mkString("," )) }
如果有多个参数
1 2 3 4 5 6 7 8 9 10 11 12 13 def main Array [String ]): Unit = { def calculator Int , b: Int , op: (Int , Int ) => Int ): Int = { op(a, b) } println(calculator(2 , 3 , (x: Int , y: Int ) => {x + y})) println(calculator(2 , 3 , (x: Int , y: Int ) => x + y)) println(calculator(2 , 3 , (x , y) => x + y)) println(calculator(2 , 3 , _ + _)) }
函数柯里化和闭包
闭包:如果一个函数,访问到了它的外部(局部)变量的值,那么这个函数和他所处的环境,称为闭包
柯里化的写法和 闭包的调用很像,建议:闭包都用柯里化写
闭包就是本质就是一个函数,只不过使用了外部变量作为返回值的函数,只是语法如果使用柯里化,可读性不一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def main Array [String ]): Unit = { def add Int ,b:Int ) = a+ b def addByA Int ) : Int => Int = { def addByB Int ) = a + b addByB } println(add(5 ,8 )) println(addByA(5 )(8 )) val addByFive = addByA(5 ) println(addByFive(16 )) def addByA1 Int ) : Int => Int = a + _ println(addByA1(3 )(4 )) def addCurrying Int )(b:Int ) = a + b val addByFour = addCurrying(5 )(53 ) println(addByFour) }
递归 阶乘
就和Java递归是差不多的,无非是方法的格式不一样
1 2 3 4 5 6 7 8 9 def main Array [String ]): Unit = { println(test(5 )) } def test Int ):Int = { if (i == 1 ) { return 1 } test(i - 1 ) * i }
控制抽象
分两种 值传递和名传递
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def f0 Int ): Unit = { println("a: " + a) println("a: " + a) } f0(23 ) def f1 Int = { println("f1调用" ) 12 } f0(f1()) def f2 Int ): Unit = { println("a: " + a) println("a: " + a) } f2(23 ) f2(f1())
惰性加载
当函数返回值被声明为 lazy 时 ,函数的执行将被推迟 ,直到我们第一次对此取值,该函数才会执行。这种函数我们称之为惰性函数。
应用点我觉得像线程的时候,会用得到,使用该方法(函数),线程执行。和线程的堵塞和锁有点类似。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def main Array [String ]): Unit = { lazy val res = sum(10 ,30 ) println("1,函数调用" ) println("2.res = " + res) } def sum Int , i1: Int ):Int = { println("3.sum 被执行。。。" ) i + i1 }
6.扩展学习部分
1 2 定义一个函数 func ,它接收一个 Int 类型的参数,返回一个函数(记作 f1 )。它返回的函数 f1 ,接收一个 String 类型的参数,同样返回一个函数(记作 f2 )。函数 f2 接收一个 Char 类型的参数,返回一个 Boolean 的值。 要求调用函数 func (0 ) (“”) (‘0 ’) 得到返回值为 false ,其它情况均返回 true 。
1 2 3 4 5 6 7 8 9 def func Int )= { def f1 String ) = { def f2 Char ) = { if (int == 0 && string == "" && char == '0 ') false else true } f2 _ } f1 _ }
全匿名函数实现
1 2 3 def func1 Int ):String => Char => Boolean = { y => z : => {if (x == 0 && y == "" && z == '0 ') false else true } }
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天是学习任务是Scala的函数式和部分面向对象,以及对未来大数据比赛的规划。Scala的函数式编程是它的特点,他和Java最大的区别,Scala不仅是函数式编程也是面向对象编程,而且比Java更面向对象,Java8更新的lambda就是借鉴Scala的函数式的。函数式会非常非常简洁,像六七行很长的代码,能缩的很短,而且比java的lambda更短,比python也要短,但是自己简化完,自己都不知道写的什么,可读性就很一言难尽。学习难度是一般,就是代码解读和后面的闭包不是很好掌握,重点还是函数式的简化吧,大部分都是在讲这个,今天状态很佳。
7.19 Scala面向对象
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1Xh411S7bP?p=79&share_source=copy_web&vd_source=c8ae4150b2286ee39a13a79bbe12b843
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 070 _尚硅谷_Scala_ 面向对象(一)_包(一)_声明和访问071 _尚硅谷_Scala_ 面向对象(一)_包(二)_包对象072 _尚硅谷_Scala_ 面向对象(一)_包(三)_导包说明073 _尚硅谷_Scala_ 面向对象(二)_类和对象074 _尚硅谷_Scala_ 面向对象(三)_封装(一)_访问权限075 _尚硅谷_Scala_ 面向对象(三)_封装(二)_构造器| | | 106 _尚硅谷_Scala_ 集合(三)_列表(二)_可变列表107 _尚硅谷_Scala_ 集合(四)_Set 集合(一)_不可变Set 108 _尚硅谷_Scala_ 集合(四)_Set 集合(二)_可变Set 109 _尚硅谷_Scala_ 集合(五)_Map 集合(一)_不可变Map110 _尚硅谷_Scala_ 集合(五)_Map 集合(二)_可变Map111 _尚硅谷_Scala_ 集合(六)_元组
3.所学内容概述
类和对象
封装
继承和多态
4.根据概述分章节描述
类和对象
定义属性语法
1 2 3 4 5 private var name : String = "alice" var age : Int = 18 @BeanProperty var sex : String = _
封装
Scala默认权限是public 但是Scala没有public关键字
protected 为受保护权限,Scala 中受保护权限比 Java 中更严格,同类、子类可以访问,同包无法访问。
private[包名]增加包访问权限,包名下的其他类也可以使用 不加包名就是私有的只能在类的内部和伴生对象中使用
构造器
和Java区别有点大,主构造器是不用声明的。
1 2 3 4 5 6 7 class 类名 (形参列表 ) def this } def this } }
继承和多态
语法和Java一样
1 2 3 class Student extends Person }
子类会继承父类的属性和方法 同样都是单继承(一个子类只能有一个父类)
继承的调用顺序:父类构造器->子类构造器
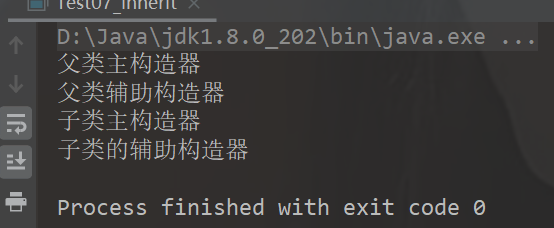
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Person (nameParam: String ) var name = nameParam var age: Int = _ def this String , ageParam: Int ) { this (nameParam) this .age = ageParam println("父类辅助构造器" ) } println("父类主构造器" ) } class Emp (nameParam: String , ageParam: Int ) extends Person (nameParam, ageParam) { var empNo: Int = _ def this String , ageParam: Int , empNoParam: Int ) { this (nameParam, ageParam) this .empNo = empNoParam println("子类的辅助构造器" ) } println("子类主构造器" ) } object Test def main Array [String ]): Unit = { new Emp ("z3" , 11 ,1001 ) } }
上面案例的运行结果是
验证了继承,创建对象先调用父类的构造器
多态
动态绑定
Scala 中属性和方法都是动态绑定,而 Java 中只有方法为动态绑定。
自己写了一个Java一个Scala的代码验证
Java多态代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class DynamicBind { public static void main (String[] args) { PersonByJava person = new PersonByJava (); System.out.println(person.name); person.hello(); PersonByJava studentByJava = new StudentByJava (); System.out.println(studentByJava.name); studentByJava.hello(); StudentByJava studentByJava1 = new StudentByJava (); System.out.println(studentByJava1.name); } } class PersonByJava { public String name = "person" ; public void hello () { System.out.println("hello person" ); } } class StudentByJava extends PersonByJava { public String name = "student" ; public void hello () { System.out.println("hello student" ); } public void hi () { System.out.println("hi student" ); } }
Scala多态代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 object Test08_DynamicBind def main Array [String ]): Unit = { val student: Person8 = new Student8 println(student.name) student.hello() } } class Person8 val name : String = "person" def hello Unit ={ println("hello person" ) } } class Student8 extends Person8 override val name : String = "student" override def hello Unit ={ println("hello student" ) } }
可见Scala的动态绑定更为的完善,Java是没有属性绑定的,Scala有。
重写
Scala重写父类的属性和方法的时候,除了类型和名称一样(和java一样),还要在属性和方法前面加上oberride修饰
1 2 3 4 5 6 class Student8 extends Person8 override val name : String = "student" override def hello Unit ={ println("hello student" ) } }
这样的好处显而易见,更为清楚明了的 告知该方法或者属性是父类重写的。
抽象类
Scala和Java一模一样,声明方法也差不多
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 object Test09_abstract def main Array [String ]): Unit = { val teacher = new Teacher9 () teacher.hello9() println(teacher.name) val workers = new Person9 { override val name: String = "workers" override def hello9 Unit = println("hello worker" ) } workers.hello9() } } abstract class Person9 val name: String def hello9 Unit } class Teacher9 extends Person9 override val name: String = "teacher" override def hello9 Unit = println("hello 9 abstract and teacher" ) }
伴生对象
伴生对象是Scala所独有的,可以通过伴生对象设计单例设计模式 懒汉式和饿汉式
基础伴生对象使用,将主构造器设计为私有,通过伴生类去调用 推荐使用apply 可以省略方法名 直接创建(和python创建对象一样了就)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 object Test10_Object def main Array [String ]): Unit = { val person2 = Person10 .newPerson10("alice" ,18 ) person2.printInfo() val person3 = Person10 .apply("bob" ,29 ) person3.printInfo() val person4 = Person10 ("akko" ,35 ) person4.printInfo() } } object Person10 def newPerson10 String ,age:Int ): Person10 = new Person10 (name,age) def apply String ,age:Int ): Person10 = new Person10 (name,age) var school: String = "ZhongCe" } class Person10 private (val name : String ,val age : Int ) def printInfo Unit ={ println(s"student: name = $name ,age = $age , school = ${Person10.school} " ) } }
特质
Scala 语言中,采用特质 trait(特征)来代替接口的概念,也就是说,多个类具有相同的特质时,就可以将这个特质(独立出来,采用关键字 trait 声明。可写可不写 。与接口不同的是,它还可以定义属性和方法的实现。
我认为和java里一样,是因为都是单继承语言,然后通过这样的方式,对单继承机制的补充 单继承多实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 object Test12_Trait def main Array [String ]): Unit = { val student12: Student12 = new Student12 student12.sysHello() student12.study() student12.dating() student12.play() } } class Person12 val name: String = "person" val age: Int = 18 def sysHello Unit ={ println("hello from: " + name) } } trait Young val age: Int val name: String = "young" def play Unit ={ println("young people is playing" ) } def dating Unit } class Student12 extends Person12 with Young override val name: String = "student" override val age: Int = 19 override def dating Unit = println(s"student $name is dating" ) def study Unit = println(s"student $name is study" ) override def sysHello Unit = { super .sysHello() println(s"hello from: student $name " ) } }
特质混用
其实就是类似于Java中一个类实现多个接口一样的概念,Java中已有的接口都可以当作Scala的特质直接使用
1 2 3 4 5 6 7 8 9 10 11 12 class Teacher extends PersonTrait with java .io .Serializable override def say Unit = { println("say" ) } override var age: Int = _ } trait Teacher trait Person class Student with Teacher with Person }
特质和抽象类的使用场景
1 2 1.优先使用特质。一个类扩展多个特质是很方便的,但却只能扩展一个抽象类。 2.如果你需要构造函数参数,使用抽象类。因为抽象类可以定义带参数的构造函数,而特质不行(有无参构造)。
5. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
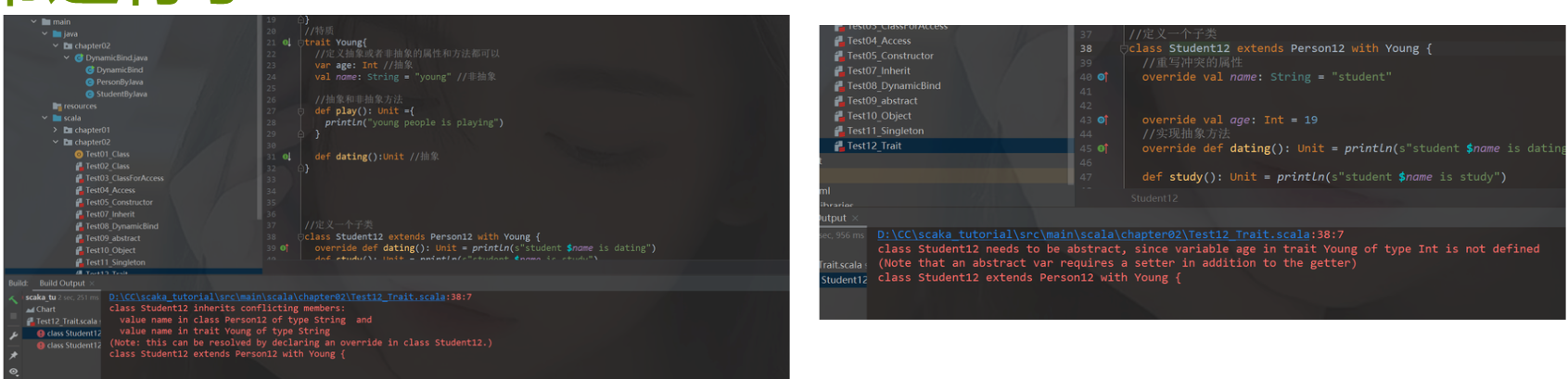
类和对象代码打完,发现运行的时候,IDEA运行的界面都没了,后面检查,发现编译没错,那就是运行错误,看提示是类的原因,结果发现自己没写main类,无法运行,Scala的这点和Java是一样的。
看报错信息,是name的问题,检查了一遍代码发现了问题,特质中声明了name,父类person也声明了name。student子类又继承又实现,应该是运行的时候,不知道调用哪个,解决办法:子类自己重写方法,让name属性使用自己的。修改完又报错,翻译是age接口的问题,var要重写set和get方法,想想算了,就把var改成了val常量,正常运行了
6.扩展学习部分
上面的第二个错误,我看弹幕也有很多人这样,就去搜了一次Scala特质这种冲突问题,发现是有解释和方法解决的。
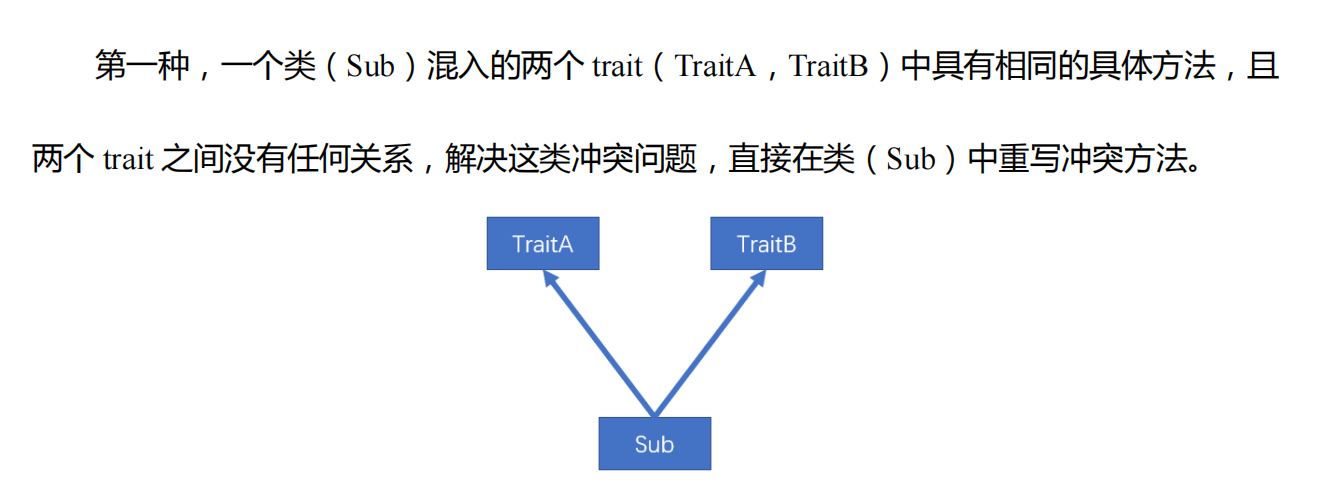
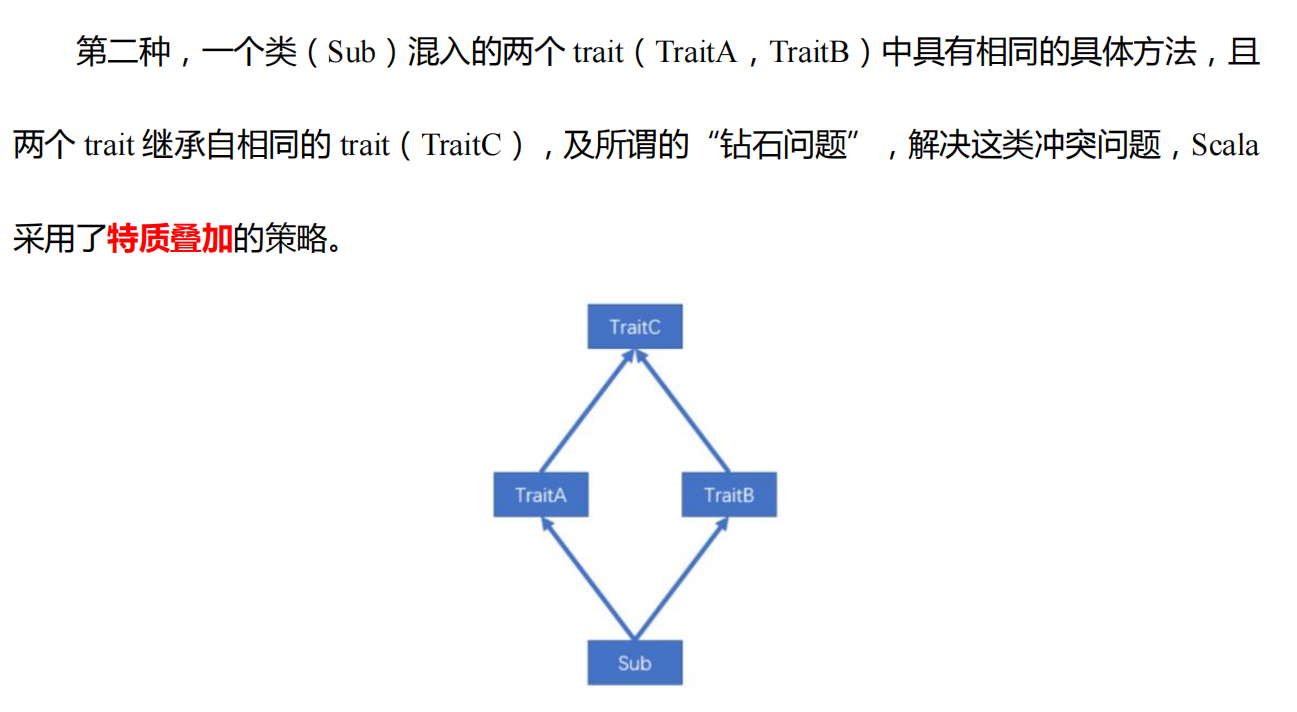
由于一个类可以混入多个 trait,且 trait 中可以有具体的属性和方法,若混入的特质中具有相同的方法(方法名,参数列表,返回值均相同),必然会出现继承冲突问题。冲突分为以下两种:继承的父类也算
我就是上图的第一种,并没有什么关联的,重写冲突方法或者属性就好了。
特质叠加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 trait Ball def describe String = { "ball" } } trait Color extends Ball override def describe String = { "blue-" + super .describe() } } trait Category extends Ball override def describe String = { "foot-" + super .describe() } } class MyBall extends Category with Color override def describe String = { "my ball is a " + super .describe() } } object TestTrait def main Array [String ]): Unit = { println(new MyBall ().describe()) } }
上图就是钻石问题了。运行结果:my ball is a blue-foot-ball
MyClass 中的 super 指代Color,Color 中的 super 指代 **Category,**Category 中的 super 指代 Ball 。
那么叠加顺序就是
MyClass ----Color ----Category—Ball
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天Scala的学习内容是面向对象这块,也是学完了,前面的封装以及继承等和Java基本没有改动,只是优化了权限。抽象类也没变化,Scala面向对象的特别之处就是升级版的接口了,特质,这点也是比较重要的点,存在一定的难度。看文档没有很会,就又去看了一遍视频,结合文档,特质的基本使用已经掌握了,还有一些混用等,代码敲多了,掌握清除没什么问题,今天的学习状态和过程都不错, 明天进入集合和元组的学习,希望能保持今天的劲头。
7.20 数组和集合
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 P91 091 _尚硅谷_Scala_ 集合(一)_集合类型系统P92 092 _尚硅谷_Scala_ 集合(二)_数组(一)_不可变数组(一)_创建数组P93 093 _尚硅谷_Scala_ 集合(二)_数组(一)_不可变数组(二)_访问和修改元素P94 094 _尚硅谷_Scala_ 集合(二)_数组(一)_不可变数组(三)_遍历数组P95 095 _尚硅谷_Scala_ 集合(二)_数组(一)_不可变数组(四)_添加元素| | 141 _尚硅谷_Scala_ 泛型(一)_概念和意义P142 142 _尚硅谷_Scala_ 泛型(二)_逆变和协变P143 143 _尚硅谷_Scala_ 泛型(三)_上下限
3.所学内容概述
Scasla集合简介
数组
列表
set集合
Map集合
元组
常用函数 方法
队列
并行集合
模式匹配
异常处理
4.根据概述分章节描述
Scala集合简介
将Java三大集合照搬了,修改了List为Seq,但是List在Scala还存在
Scala 的集合有三大类:序列 Seq、集 Set、映射 Map,所有的集合都扩展自 Iterable特质。
对于几乎所有的集合类,Scala 都同时提供了可变 和不可变 的版本
Scala 不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象
可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。
数组
可变和不可变都放下面的案例练习了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package chapter03import scala.collection.mutable.ArrayBuffer object Test01_Array def main Array [String ]): Unit = { val arr01 = new Array [Int ](9 ) arr01.update(1 ,4 ) println(arr01.mkString("," )) val arr1 = Array (1 ,4 ,5 ,6 ,6 ,9 ,"jack" ) println("arr1长度:" + arr1.length) arr1.foreach(print) println() println("-----------------------" ) println(arr01) val ints: Array [Int ] = arr01 :+ 5 println(ints) println("-----------------------" ) val arr2 = ArrayBuffer [Any ](1 ,2 ,3 ,"helen" ) println("arr2长度:" +arr2.length) println(arr2.mkString("," )) println("arr2.hash= " + arr2.hashCode()) arr2.+=(4 ) println(arr2.mkString("," )) arr2.append(5 ,6 ) println(arr2.mkString("," )) arr2.insert(1 ,7 ,0.8 ) println(arr2.mkString("," )) println("arr2.hash= " + arr2.hashCode()) arr2(5 ) = "kiss" println(arr2.mkString("," )) } }
运行结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 0 ,4 ,0 ,0 ,0 ,0 ,0 ,0 ,0 arr1长度:7 145669 jack----------------------- [I @22 f71333 [I @13969 fbe ----------------------- arr2长度:4 1 ,2 ,3 ,helenarr2.hash= 100581814 1 ,2 ,3 ,helen,4 1 ,2 ,3 ,helen,4 ,5 ,6 1 ,7 ,0.8 ,2 ,3 ,helen,4 ,5 ,6 arr2.hash= -18482605 1 ,7 ,0.8 ,2 ,3 ,kiss,4 ,5 ,6 Process finished with exit code 0
可变数组和不可变数组的转换
对原本的数组没有改变,方法返回一个新数组
1 2 3 4 5 arr1.toBuffer arr2.toArray (1 )arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化 (2 )arr1.toBuffer 返回结果才是一个可变数组,arr1 本身没有变化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 object Test02_ArrayChange def main Array [String ]): Unit = { val arr2 = ArrayBuffer [Int ]() arr2.append(1 ,2 ,5 ) println(arr2) val newArr:Array [Int ] = arr2.toArray println(newArr.mkString("--" )) val newArr2 = newArr.toBuffer newArr2.append(123 ) println(newArr2) } }
多维数组
这个和Java一样,用处也不是很大感觉,过了一遍,很容易理解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 object Test03_DimArray def main Array [String ]): Unit = { val arr = Array .ofDim[Int ](3 ,4 ) arr(1 )(2 ) = 88 for (i <- arr){ for (j <- i){ print(j + " " ) } println() } } }
列表List
不可变List
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 object Test04_List def main Array [String ]): Unit = { val list: List [Int ] = List (1 ,2 ,3 ,4 ,3 ) list.foreach(println) println(list.mkString("--" )) val list1 = 7 :: 9 :: 8 :: list println(list1.mkString("--" )) val list2 = list1 .+:(10 ) println(list2.mkString("--" )) val list3 = List (8 ,9 ,53 ) val list4 = list3 ::: list2 println(list4.mkString("," )) } }
可变ListBuffer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 object Test05_ListChange def main Array [String ]): Unit = { val buffer = ListBuffer (1 ,2 ,3 ,4 ) buffer.+=(5 ) buffer.append(6 ) buffer.insert(1 ,2 ) buffer.foreach(print) println() println(buffer.mkString("-" )) buffer(1 ) = 6 buffer.update(1 ,7 ) buffer.-(5 ) buffer.-=(5 ) buffer.remove(5 ) println(buffer.mkString("-" )) } }
Set集合
Set 默认是不可变集合,数据无序 数据不能重复
1 2 3 4 5 6 7 8 9 10 11 12 13 object Test06_Set def main Array [String ]): Unit = { val set = Set (1 ,2 ,3 ,4 ,5 ,7 ) println(set.mkString("," )) val set1 = Set (1 ,2 ,3 ,4 ,5 ,6 ,3 ) for (x<-set1){ println(x) } } }
mutable.Set可变集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 object Test07_MutableSet def main Array [String ]): Unit = { val set = mutable.Set (1 ,2 ,3 ,4 ,5 ,7 ) println(set.mkString("-" )) set += 8 println(set.mkString("-" )) val ints = set.+(9 ) println(ints) println("set2=" + set) set-=(5 ) } }
Map集合
Scala 中的 Map 和 Java 类似,也是一个散列表 ,它存储的内容也是键值对(key-value )映射
不变的Map是有序的 可变的Map是无序的
不可变Map
如果 key 不存在,返回 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 object Test08_Map def main Array [String ]): Unit = { val map = Map ( "a" ->"A" , "b" ->2 , "c" ->3 ) map.foreach(println) for (elem <- map.keys){ println(elem + "=" + map(elem)) } println(map.getOrElse("s" ,5 )) } }
可变Map
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 object Test09_MapChange def main Array [String ]): Unit = { val map = mutable.Map ( "a" ->1 , "b" ->2 , "c" ->3 ) println(map.mkString(" , " )) map.+=("d" ->4 ) println(map.mkString(" , " )) val maybeInt = map.put("a" , 4 ) println(map.mkString(" , " )) println(maybeInt) println(maybeInt.getOrElse(0 )) println(map.-=("b" , "c" )) println(map.mkString(" , " )) map.update("d" ,5 ) map("a" ) = 1 println(map.mkString(" , " )) } }
元组
元组算是一个容器,可以这么理解,就是可加将很多无关的数据封装为一个整体 元组最大只能有22个元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 object Test10_Tuple def main Array [String ]): Unit = { val tuple = (40 ,"bobo" ,true ) println(tuple._1) println(tuple._2) println(tuple._3) println(tuple.productElement(1 )) for (elem <- tuple.productIterator) { println(elem) } val map = Map ("a" ->1 , "b" ->2 , "c" ->3 ) val map1 = Map (("a" ,1 ), ("b" ,2 ), ("c" ,3 )) map.foreach(tuple1=>{println(tuple1._1 + "=" + tuple1._2)}) map1.foreach(tuple1=>{println(tuple1._1 + "=" + tuple1._2)}) } }
集合常用函数
基本属性和常用操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 object Test01_TestList def main Array [String ]): Unit = { val list: List [Int ] = List (1 , 2 , 3 , 4 , 5 , 6 , 7 ) println(list.length) println(list.size) list.foreach(println) for (elem <- list.iterator) { println(elem) } println(list.mkString("," )) println(list.contains(3 )) } }
衍生集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 object Test02_TestListPlus def main Array [String ]): Unit = { val list1: List [Int ] = List (1 , 2 , 3 , 4 , 5 , 6 , 7 ,11 ) val list2: List [Int ] = List (4 , 5 , 6 , 7 , 8 , 9 , 10 ) println(list1.head) println(list1.tail) println(list1.last) println(list1.init) println(list1.reverse) println(list1.mkString("," )) println(list1.take(4 )) println(list1.takeRight(3 )) println(list1.drop(3 )) println(list1.dropRight(3 )) println(list1.mkString("," )) println(list1.union(list2)) println(list1.intersect(list2)) println(list1.diff(list2)) println(list1.mkString("," )) list1.sliding(2 , 5 ).foreach(println) println("拉链" ) println(list1.zip(list2)) } }
集合计算简单函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 object Test03_ListMath def main Array [String ]): Unit = { val list: List [Int ] = List (1 , 5 , -3 , 4 , 2 , -7 , 6 ) println(list.sum) println(list.product) println(list.max) println(list.min) println(list.sorted) println(list.sortBy(x => x)) println(list.sortBy(x => x.abs)) println(list.sortWith((x, y) => x < y)) println(list.sortWith((x, y) => x > y)) } }
集合计算高级函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 object Test04_HighLevelFunction_Map def main Array [String ]): Unit = { val list = List (1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ) println(list.filter(_ % 2 == 0 )) println(list.filter(_ % 2 == 1 )) println("=========================" ) println(list.map(_ * 2 )) println(list.map(x => x * x)) println("=========================" ) val nestedList: List [List [Int ]] = List (List (1 ,2 ,3 ),List (4 ,5 ),List (6 ,7 ,8 ,9 )) println(nestedList.flatten) val wordList: List [String ] = List ("hello world" , "hello atguigu" , "hello scala" ) println(wordList.flatMap(_.split(" " ))) println(list.groupBy(_ % 2 == 0 )) } }
队列
Scala 也提供了队列(Queue)的数据结构,队列的特点就是先进先出。进队和出队的方法分别为 enqueue 和 dequeue。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 object Test11_Queue def main Array [String ]): Unit = { val que = new mutable.Queue [String ]() que.enqueue("a" ,"b" ,"c" ) println(que.dequeue()) que.enqueue("T" ) println(que.dequeue()) println(que.dequeue()) println(que.dequeue()) } }
并行集合
是一种利用多核CPU的集合,进行多核的并行运算
1 2 3 4 5 6 7 8 object Test12_Par def main Array [String ]): Unit = { val result1 = (0 to 100 ).map(_ => Thread .currentThread.getName) val result2 = (0 to 100 ).par.map(_ => Thread .currentThread.getName) println(result1) println(result2) } }
结果
可见原本的集合是一直都是main线程,而par的则是利用了不同的核心,这样使得 集合创建和运行的效率大大提高。
异常处理
和java一模一样,只有catch部分有区别,Catch在java中多异常的时候,多写几个Catch就好了,在Scala则是多写几个Case。具体实现代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 object Test01_Exception def main Array [String ]): Unit = { try { val n= 10 / 0 println(n) }catch { case _: ArithmeticException => println("发生算术异常" ) case _: Exception => println("发生了异常 1" ) println("发生了异常 2" ) }finally { println("finally" ) } }
抛出异常 关键字和java一样都是throw
下面是自己写了一个异常处理嵌套的简单代码,我理解Scala和Java异常处理是没有大变化的
区别点在异常捕获机制等,看文档,不重要没有深究
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 object Test02_ExceptionThrow def main Array [String ]): Unit = { try { test1() } catch { case _: Exception => println("报错咯" ) } finally { try { f11() }catch { case _: ArithmeticException => println("发生算术异常0" ) case _: Exception => println("发生了异常 1" ) println("发生了异常 2" ) }finally { println("finally" ) } } } @throws (classOf[NumberFormatException ]) def f11 "abc" .toInt } def test1 Nothing = { throw new Exception ("不可以哦" ) } }
模式匹配
我感觉像是switch的超级升级版,基础使用的话是差不多的,但是Scala用上闭包和柯里化,能让模式匹配变得很强大,可以代替If函数。
如下是基础使用,了解语法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 object Test01_MatchCase def main Array [String ]): Unit = { println("请输入第一个数字:" ) val a: Int = StdIn .readInt() println("请输入你要进行的操作 (+ - * /)" ) val c = StdIn .readChar() println("请输入第二个数字:" ) val b: Int = StdIn .readInt() def result Char ) = x match { case '+' => a + b case '-' => a - b case '*' => a * b case '/' => a / b case _ => "illegal" } println("请输入你要进行的操作 (+ - * /)" ) val value = result(c) println(s"$a $c $b = $value " ) } }
可以通过_来进行输入类型判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 object Test02_MatchVal def main Array [String ]): Unit = { println(describe(6 )) println(describe(List (1 , 2 , 3 , 4 , 5 ))) println(describe(Array (1 , 2 , 3 , 4 , 5 , 6 ))) println(describe(Array ("abc" ))) } def describe Any ) = x match { case i: Int => "Int" case s: String => "String hello" case m: List [_] => "List" case c: Array [Int ] => "Array[Int]" case someThing => "something else " + someThing } }
模式匹配的用法很多,但大致使用都一样,就不一一列举了。
5.BUG点
自己写扩展练习的时候,报错了,因为自己对Scala中元组的._这用法不是很熟悉,都是边看笔记边敲出来,看提示信息,是16行类型出现的问题,我先把前面声明类型删除了,让系统自己去匹配类型,结果后面又会有一条报错,来回检查发现x._2是Map变成的list,而我要做的的是统计次数,因此后面应该是x._2的size或者length方法,统计出list的长度。
6.扩展学习部分
记数排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 object Test07_subject def main Array [String ]): Unit = { val stringList = List ("Hello Scala Hbase kafka" , "Hello Scala Hbase" , "Hello Scala" , "Hello" ) val wordList: List [String ] = stringList.flatMap(_.split(" " )) println(wordList) val wordToMap: Map [String ,List [String ]] = wordList.groupBy(a => a) println(wordToMap) val wordToMapCount: Map [String ,Int ] = wordToMap.map(x => (x._1, x._2.size)) println(wordToMapCount) val wordListToCount : List [(String , Int )]= wordToMapCount.toList val sortList =wordListToCount.sortWith { (x, y) => { x._2 > y._2 } } println(sortList.take(3 )) } }
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的学习状态非常不错,已经熟练掌握了看文档的技能了,一天看了将近视频的70集。Scala后面的面向对象和集合方面都是以代码为主,逻辑性的问题,在Java早就牢记于心了,看文档的案例,复制到IDEA,自己基本就能分析出来方法的作用,以及使用场景。难点和Scala独特的点是同一点,就是元组的._使用,._能很大程度上优化Scala的代码长度,让代码更简洁,而且._匿名调用集合中的元素,以及列表中嵌元组,Map集合中嵌列表,二维列表中是偶元组,这种场景下,就显得非常好用,在for循环遍历也是如此。元组还是Scala比较重要,实用的点。今日算超额完成任务了,进入了Spark的学习,配置好了基本环境,将快速上手小案例做了出来,有前面Hadoop的铺垫,Spark理解应该会稍微容易点的,希望明天正式进入Spark的学习状态能和今天一样吧。
7.21 Spark入门
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 P1001 .尚硅谷_Spark框架 - 简介 4 :54 P2002 .尚硅谷_Spark框架 - Vs Hadoop 7 :49 P3003 .尚硅谷_Spark框架 - 核心模块 - 介绍 2 :24 P4004 .尚硅谷_Spark框架 - 快速上手 - 开发环境准备 5 :46 P5005 .尚硅谷_Spark框架 - 快速上手 - WordCount - 案例分析 7 :57 P6006 .尚硅谷_Spark框架 - 快速上手 - WordCount - Spark环境 7 :07 P7007 .尚硅谷_Spark框架 - 快速上手 - WordCount - 功能实现 11 :56 P8008 .尚硅谷_Spark框架 - 快速上手 - WordCount - 不同的实现 8 :31 P9009 .尚硅谷_Spark框架 - 快速上手 - WordCount - Spark的实现 4 :24 P10010 .尚硅谷_Spark框架 - 快速上手 - WordCount - 日志和错误 3 :50 P11011 .尚硅谷_Spark框架 - 运行环境 - 本地环境 - 基本配置和操作 8 :11 P12012 .尚硅谷_Spark框架 - 运行环境 - 本地环境 - 提交应用程序 3 :10 P13013 .尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 基本配置和操作 6 :13 P14014 .尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 提交参数解析 3 :08 P15015 .尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 配置历史服务 4 :08 P16016 .尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 配置高可用 5 :51 P17017 .尚硅谷_Spark框架 - 运行环境 - Yarn环境 - 基本配置 & 历史服务 6 :42 P18018 .尚硅谷_Spark框架 - 运行环境 - Windows环境 & 总结 11 :06 P19019 .尚硅谷_Spark框架 - 核心组件 - 介绍 3 :33 P20020 .尚硅谷_Spark框架 - 核心概念 - Executor & Core & 并行度 3 :31 P21021 .尚硅谷_Spark框架 - 核心概念 - DAG & 提交流程 & Yarn两种部署模式 7 :00 P22022 .尚硅谷_SparkCore - 分布式计算模拟 - 搭建基础的架子 12 :48 P23023 .尚硅谷_SparkCore - 分布式计算模拟 - 客户端向服务器发送计算任务 10 :50 P24024 .尚硅谷_SparkCore - 分布式计算模拟 - 数据结构和分布式计算 11 :39 P25025 .尚硅谷_SparkCore - 核心编程 - RDD - 概念介绍 5 :31 P26026 .尚硅谷_SparkCore - 核心编程 - RDD - IO基本实现原理 - 1 10 :11 P27027 .尚硅谷_SparkCore - 核心编程 - RDD - IO基本实现原理 - 2 8 :49 P28028 .尚硅谷_SparkCore - 核心编程 - RDD - RDD和IO之间的关系 12 :24 P29029 .尚硅谷_SparkCore - 核心编程 - RDD - 特点 13 :34 P30030 .尚硅谷_SparkCore - 核心编程 - RDD - 五大主要配置 11 :19 P31031 .尚硅谷_SparkCore - 核心编程 - RDD - 执行原理 3 :05 P32032 .尚硅谷_SparkCore - 核心编程 - RDD - 创建 - 内存 11 :02 P33033 .尚硅谷_SparkCore - 核心编程 - RDD - 创建 - 文件 6 :28 P34034 .尚硅谷_SparkCore - 核心编程 - RDD - 创建 - 文件1 4 :42 P35035 .尚硅谷_SparkCore - 核心编程 - RDD - 集合数据源 - 分区的设定 11 :41 P36036 .尚硅谷_SparkCore - 核心编程 - RDD - 集合数据源 - 分区数据的分配 13 :54 P37037 .尚硅谷_SparkCore - 核心编程 - RDD - 文件数据源 - 分区的设定 11 :33 P38038 .尚硅谷_SparkCore - 核心编程 - RDD - 文件数据源 - 分区数据的分配 8 :21 P39039 .尚硅谷_SparkCore - 核心编程 - RDD - 文件数据源 - 分区数据的分配 - 案例分析 6 :13
3.所学内容概述
Spark的快速上手
Spark在Linux的部署配置
RDD简介 和 逻辑以及执行过程 原理
4.根据概述分章节描述
Spark的快速上手
Spark 由 Scala 语言开发的,所以本课件接下来的开发所使用的语言也为 Scala
在IDEA中创建Maven项目
增加依赖
1 2 3 4 5 6 7 <dependencies > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-core_2.12</artifactId > <version > 3.0.0</version > </dependency > </dependencies >
WorldCount案例
这个案例昨天拿scala刚做过 基本逻辑是一样的,但是在Spark框架有更简单的方法,作者已经提供,不同的是要先建立和框架的连接 再去执行操作,看得出来,底层源码都是Scala
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package BigDataSparkDay1 .wcimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark01_wordCount def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setMaster("local" ).setAppName("WordCount" ) val sc = new SparkContext (conf) val fileRDD: RDD [String ] = sc.textFile("../bigdata/datas" ) val wordRDD: RDD [String ] = fileRDD.flatMap( _.split(" " ) ) val WorldToOne :RDD [(String ,Int )] = wordRDD.map((_, 1 )) val wordCount = WorldToOne .reduceByKey(_ + _) val word2Count = wordCount.collect() word2Count.foreach(println) sc.stop() } }
RDD简介
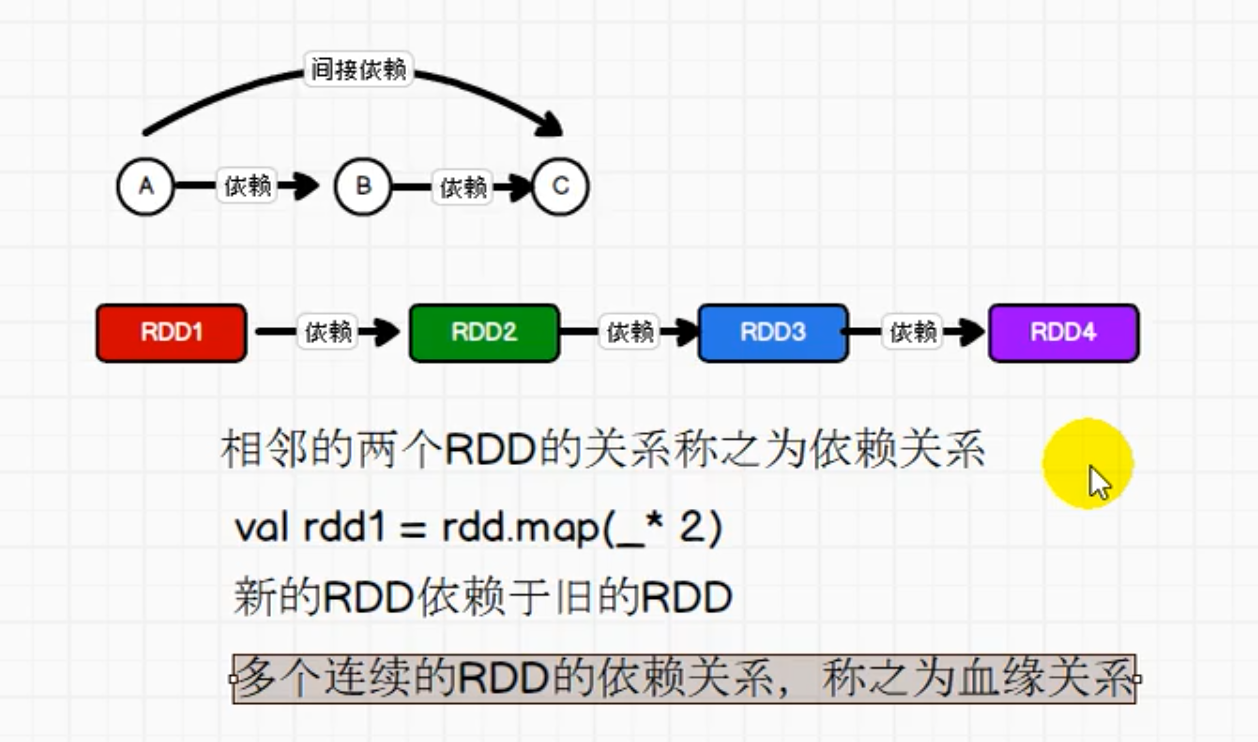
弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合
自己理解:RDD的弹性安全性比较好,高容错,适合开发。它是一个集合,但并不保存数据,而且封装了计算逻辑,同时也是一个抽象类,需要其他的子类来具体实现。
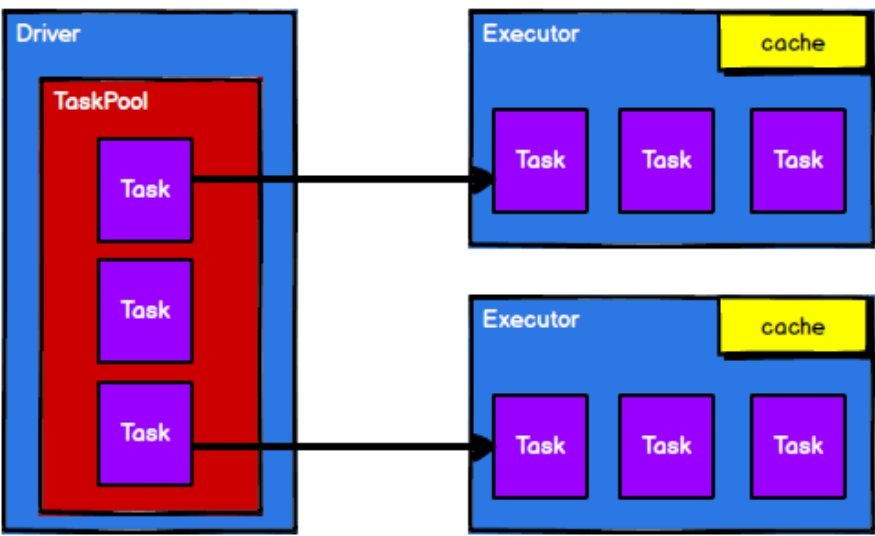
执行原理
RDD先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
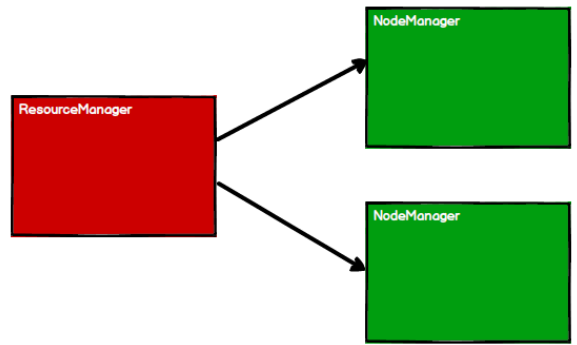
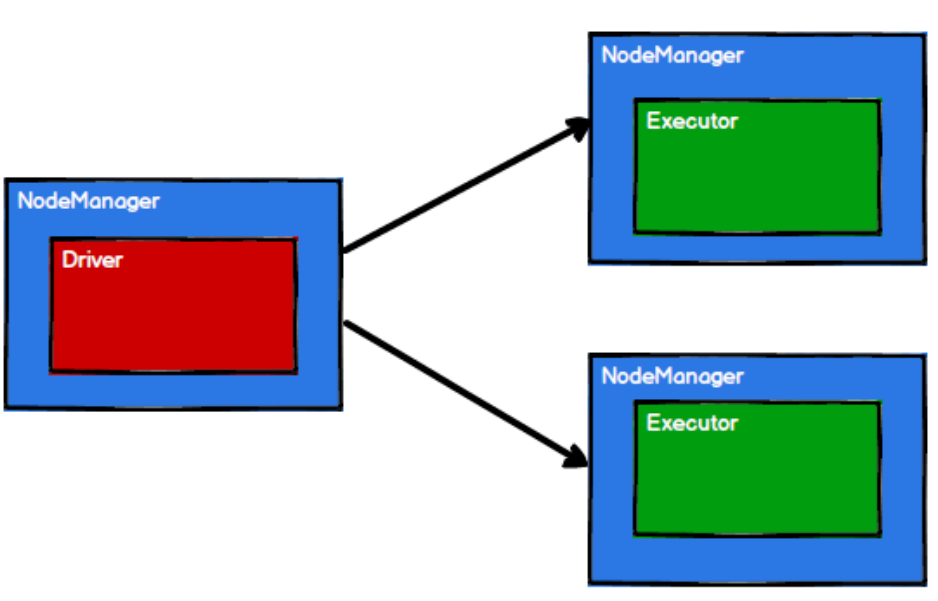
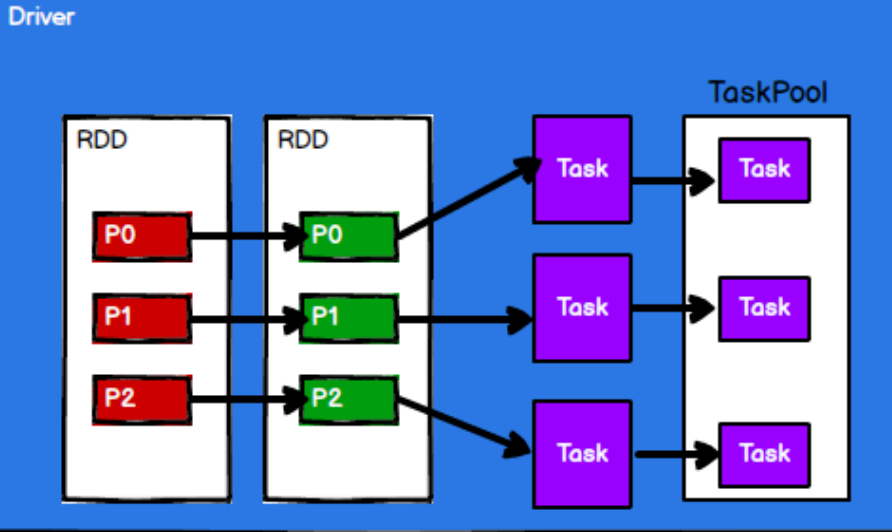
在Yarn中的执行原理
1.启动环境
2.Spark通过申请资源创建节点
3.根据需求根据分区划分任务
4.调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
如下图
根据这四幅图,便能看出来RDD的 流程中的作用主要就是将逻辑封装,生成Task也就是任务点,发送给Executor节点
RDD创建
在 Spark 中创建 RDD 的创建方式可以分为四种:
在文件中创建RDD 用makeRDD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package BigDataSparkDay1 .wcimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object SPark02_RDD_Memory def main Array [String ]): Unit = { val sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("RDD" ) val sc = new SparkContext (sparkConf) val seq = Seq [Int ](1 ,2 ,3 ,4 ) val rdd = sc.makeRDD(seq) rdd.collect().foreach(println) sc.stop() } }
剩下三种暂时说是用不到
RDD读取文件 路径问题
代码注解中已经解释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package BigDataSparkDay1 .wcimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object SPark03_RDD_File def main Array [String ]): Unit = { val sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("RDD" ) val sc = new SparkContext (sparkConf) val rdd:RDD [(String ,String )] = sc.wholeTextFiles("datas" ) rdd.collect().foreach(println) sc.stop() } }
总结:
RDD的使用在IDEA中,大致分为三步 准备环境 创建RDD 关闭环境
准备环境的代码基本很固定 而创建RDD 就要看是读取文件 还是直接在IDEA中配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package BigDataSparkDay1 .wcimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object SPark02_RDD_Memory2 def main Array [String ]): Unit = { val sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("RDD" ) sparkConf.set("spark.default.parallelism" ,"5" ) val sc = new SparkContext (sparkConf) val rdd = sc.makeRDD( List (1 ,2 ,3 ,4 ) ) rdd.saveAsTextFile("output" ) sc.stop() } }
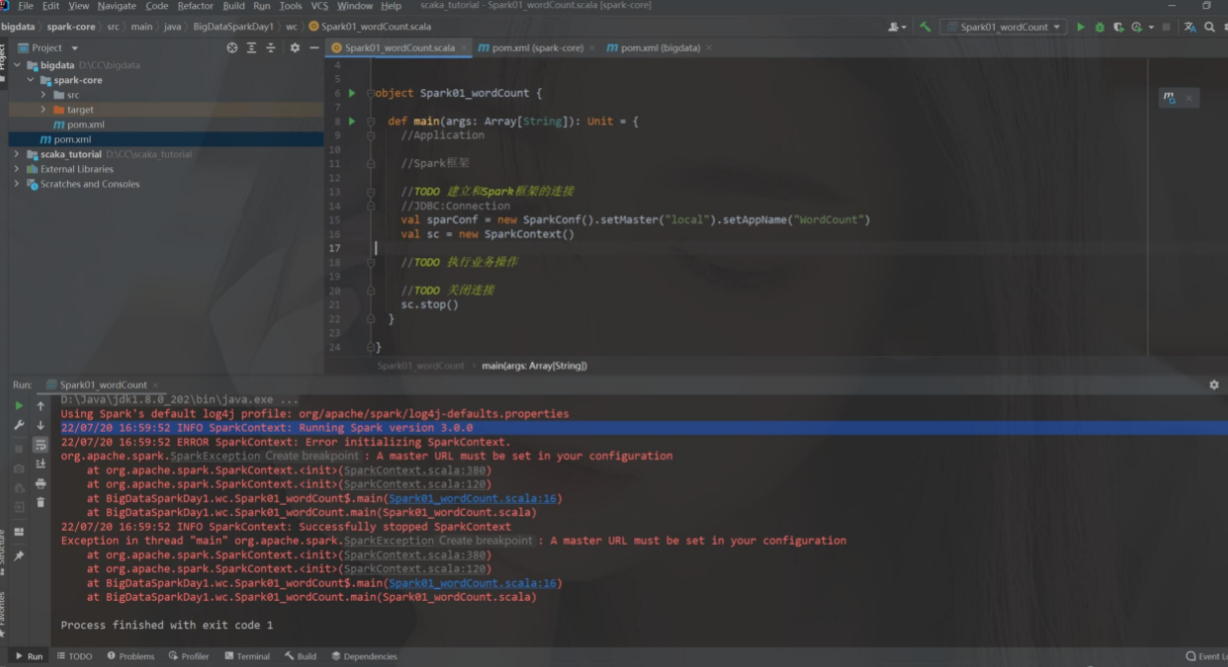
5.BUG点
跟老师一模一样的代码报错,刚进入也不知道什么原因就按报错信息去CSDN搜,发现有人有一样的问题,在resources中配置一个log4j文件就好了,也不是刚开始怀疑的版本问题
6.扩展学习部分
Linux中Spark部署
步骤 克隆三台虚拟机
修改IP地址 主机名 和 映射
配置无密 创建xsync文件并配置信息 给其增加执行权限
下载rsync yum
分发命令sbin/start -all.sh
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
昨天配置了spark在IDEA中的环境,并没有入门,今天对Spark进行一个上手入门,发现Spark框架,都是使用scala代码进行功能实现的,然后就是Linux系统中,Spark的环境部署,和框架搭建,因为不是自己负责的板块,听听作用就过去了,后面弄懂了什么是Spark以及执行原理和流程。今天难度还是有的,都是概念性的东西,要一个一个去记住和理解,明天就是转子算法的学习,就会有代码量了。
7.22 Spark-RDD转换算子
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 P40040 .尚硅谷_SparkCore - 核心编程 - RDD - 算子介绍 7 :49 P41041 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - map 7 :46 P42042 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - map - 小功能 5 :12 P43043 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - map - 并行计算效果演示 8 :54 P44044 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - mapPartitions 6 :12 P45045 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - mapPartitions - 小练习 3 :49 P46046 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - mapPartitions & map的区别 - 完成比完美更重要P47047 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - mapPartitionsWithIndex 6 :30 P48048 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - flatMap 5 :07 P49049 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - flatMap - 小练习 2 :41 P50050 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - glom 6 :33 P51051 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - 理解分区不变的含义 6 :48 P52052 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - groupBy 5 :25 P53053 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - groupBy - shuffle来袭 6 :01 P54054 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - groupBy - 小练习 7 :51 P55055 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - filter - 数据倾斜 7 :11 P56056 .尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - sample - 抽奖喽 16 :11 057Core - 核心编程 - RDD - 转换算子 - distinct058Core - 核心编程 - RDD - 转换算子 - coalesce059Core - 核心编程 - RDD - 转换算子 - repartition060Core - 核心编程 - RDD - 转换算子 - sortBy061Core - 核心编程 - RDD - 转换算子 - 交集&并集&差集&拉链062Core - 核心编程 - RDD - 转换算子 - 交集&并集&差集&拉链 - 注意事项063Core - 核心编程 - RDD - 转换算子 - partitionBy(前面有吸气,中间有等待)064Core - 核心编程 - RDD - 转换算子 - partitionBy - 思考的问题065Core - 核心编程 - RDD - 转换算子 - reduceByKey066Core - 核心编程 - RDD - 转换算子 - groupByKey067Core - 核心编程 - RDD - 转换算子 - groupByKey & reduceByKey的区别068Core - 核心编程 - RDD - 转换算子 - aggregateByKey069Core - 核心编程 - RDD - 转换算子 - aggregateByKey - 图解070Core - 核心编程 - RDD - 转换算子 - foldByKey071Core - 核心编程 - RDD - 转换算子 - aggregateByKey - 小练习072Core - 核心编程 - RDD - 转换算子 - aggregateByKey - 小练习 - 图解073Core - 核心编程 - RDD - 转换算子 - combineByKey074Core - 核心编程 - RDD - 转换算子 - 聚合算子的区别075Core - 核心编程 - RDD - 转换算子 - join076Core - 核心编程 - RDD - 转换算子 - leftOuterJoin & rightOuterJoin077Core - 核心编程 - RDD - 转换算子 - cogroup078Core - 核心编程 - RDD - 案例实操 - 需求介绍 & 分析079Core - 核心编程 - RDD - 案例实操 - 需求设计080Core - 核心编程 - RDD - 案例实操 - 功能实现081Core - 核心编程 - RDD - 行动算子 - 介绍082Core - 核心编程 - RDD - 行动算子 - 算子演示083Core - 核心编程 - RDD - 行动算子 - aggregate084Core - 核心编程 - RDD - 行动算子 - countByKey & countByValue085Core - 核心编程 - RDD - WordCount不同的实现方式 - (1 -8 )086Core - 核心编程 - RDD - WordCount不同的实现方式 - (9 -11 )087Core - 核心编程 - RDD - 行动算子 - save的方法088Core - 核心编程 - RDD - 行动算子 - foreach089Core - 核心编程 - RDD - 序列化 - 闭包检测090Core - 核心编程 - RDD - 序列化 - 实际执行时的问题
3.所学内容概述
4.根据概述分章节描述
RDD单Value转换算子
RDD根据处理方式的不同分为了Value类型 双Value 和Key-Value类型
代码都是在昨天三大步骤的基础上进行,改变点在创建RDD中,
看得出 如下代码是将List集合中每个值都*2 然后打印出来 用map方法转换 映射转换 在Scala的高级算法中有说明
map
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark01_RDD_Operator_Transform def main Array [String ]): Unit = { val sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [Int ] = sc.makeRDD(List (1 ,2 ,3 ,4 )) val mapRDD: RDD [Int ] = rdd.map((_: Int ) * 2 ) mapRDD.collect().foreach(println) sc.stop() } }
如上map方法的执行效率会很低,因为是读一个执行一次,这样需要执行多次,就像IO中对文件的处理一样,IO流解决办法是使用缓冲流Buffer,在Spark也有一种方法类似,
mapPartitions
将待处理的数据以分区为单位发送到计算节点进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package BIgDataSparkDay2 import org.apache.spark.{SparkConf , SparkContext }object Spark01_RDD_Operator_Transform_partitions def main Array [String ]): Unit = { val sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd = sc.makeRDD(List (1 , 2 , 3 , 4 ),2 ) val rddMapPartitions = rdd.mapPartitions( iter => { println(">>>>>>" ) iter.map(_ * 2 ) } ) rddMapPartitions.collect().foreach(println) sc.stop() } }
看案例的执行结果,能分析出来mapPartitions是分区操作的,比如案例两个分区,就先执行一个分区,再是另外一个,性能是比map高的,缺点 写在代码里面了
mapPartitionsWithIndex
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引 。
小案例 获取数据分区的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark01_RDD_Operator_Transform_partitionsWithIndex_Test def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [Int ] = sc.makeRDD(List (1 , 2 , 3 , 4 ),3 ) val rddMap:RDD [(Int ,Int )] = rdd.mapPartitionsWithIndex( (index: Int , iter: Iterator [Int ]) => { iter.map( (num: Int ) => { (index, num) } ) } ) rddMap.collect().foreach(println) sc.stop() } }
flatMap
将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射
将 List(List(1,2),3,List(4,5))进行扁平化操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark02_RDD_Operator_Transform_TestFlat2 def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [Any ] = sc.makeRDD(List (List (1 ,2 ),3 ,List (4 ,5 ))) val rddMap: RDD [Any ] = rdd.flatMap { case list1: List [_] => list1 case dat => List (dat) } rddMap.collect().foreach(println) sc.stop() } }
glom
将同一个分区的数据直接转换为相同类型的内存数组进行处理 看代码执行过后是返回一个数组类型的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark02_RDD_Operator_Transform_Glom def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [Int ] = sc.makeRDD(List (1 ,2 ,3 ,4 ),2 ) val glom: RDD [Array [Int ]] = rdd.glom() val glomRDD: RDD [Int ] = glom.map( (array: Array [Int ]) => { array.max } ) println(glomRDD.collect().foreach((data: Int ) => print(data + "," ))) println(glomRDD.sum()) sc.stop() } }
groupBy
将数据源中的每个数据进行分组判断 根据返回的分组key 进行分组 相同的key值会放在一个组中
注意分组和分区没有必然的关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark04_RDD_Operator_Transform_GlomBy def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [String ] = sc.makeRDD(List ("Hello" ,"Spark" ,"Scala" ,"Hadoop" ),2 ) val groupRDD: RDD [(Char , Iterable [String ])] = rdd.groupBy((_: String )(0 )) groupRDD.collect().foreach(println) sc.stop() } }
groupBy会把不同区的数据打乱,重新组合,这个操作我们称为shuffle
filter
当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜 了解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark05_RDD_Operator_Transform_filter_Test def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd = sc.textFile("datas/apache.log" ) val rddFilter: RDD [String ] = rdd.filter( line => { val time = line.split(" " )(3 ) time.startsWith("17/05/2015" ) } ) rddFilter.collect().foreach(println) sc.stop() } }
sample
根据指定的规则从数据集中抽取数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark06_RDD_Operator_Transform_sample def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val dataRDD: RDD [Int ] = sc.makeRDD(List (1 , 2 , 3 , 4 ,5 ,6 ,7 ,8 ,9 ,10 ,11 )) val dataRDD1: RDD [Int ] = dataRDD.sample(withReplacement = false , 0.5 ) val dataRDD2: RDD [Int ] = dataRDD.sample(withReplacement = true , 2 ) println("不放回" ) println(dataRDD1.collect().mkString("," )) println("放回" ) println(dataRDD2.collect().mkString("," )) sc.stop() } }
distinct
将数据集中重复的数据去重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark07_RDD_Operator_Transform_distinct def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val dataRDD: RDD [Int ] = sc.makeRDD(List (1 ,2 ,3 ,4 ,6 ,6 ,1 ,2 ,3 ,4 ,5 ,7 ,5 ,6 ,9 ,7 ,21 ,6 ,2 )) val value: RDD [Int ] = dataRDD.distinct() val value1: RDD [Int ] = dataRDD.distinct(2 ) println(value.collect().mkString("," )) println(value1.collect().mkString("," )) sc.stop() } }
coaleses(可增大 可减小)
对增减分区的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark08_RDD_Operator_Transform_coalesce def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val dataRDD: RDD [Int ] = sc.makeRDD(List (1 ,2 ,3 ,4 ,1 ,2 ),6 ) val dataRDD1: RDD [Int ] = dataRDD.coalesce(2 ,true ) val dataRDD1Index = dataRDD1.mapPartitionsWithIndex( (index: Int , group: Iterator [Int ]) => { group.map( (num:Int ) => (index,num) ) } ) dataRDD1Index.collect().foreach(println) sc.stop() } }
repartition
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark09_RDD_Operator_Transform_repartition def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val dataRDD: RDD [Int ] = sc.makeRDD(List (1 ,2 ,3 ,4 ,1 ,2 ),2 ) val dataRDD2: RDD [Int ] = dataRDD.repartition(4 ) val dataRDD2Index: RDD [(Int , Int )] = dataRDD2.mapPartitionsWithIndex( (index: Int , group: Iterator [Int ]) => { group.map( (num:Int ) => (index,num) ) } ) dataRDD2Index.collect().foreach(println) sc.stop() } }
coalesce 和 repartition 区别
repartition 一定会发生 shuffle,coalesce 根据传进来的参数来判断是否发生 shuffle。增大rdd的partition数量 使用repartition ,减少partition数量时 使用coalesce
sortBy
该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序
排序是不管多少分区的,所以sortBy执行过程一定存在shuffle打乱的过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark10_RDD_Operator_Transform_sortBy def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val dataRDD: RDD [(String , Int )] = sc.makeRDD(List (("1" ,1 ),("11" ,2 ),("2" ,3 ))) val dataRDD1: RDD [(String , Int )] = dataRDD.sortBy((t: (String , Int )) => t._1.toInt,ascending = false ) println(dataRDD1.collect().mkString("," )) sc.stop() } }
RDD双Value转换算子
两个数据源之间的关联操作
集合基本操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark11_RDD_Operator_Transform_DoubleValue def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val dataRDD1 = sc.makeRDD(List (1 ,2 ,3 ,4 )) val dataRDD2: RDD [Int ] = sc.makeRDD(List (3 ,4 ,5 ,6 )) val dataRDDIn = dataRDD1.intersection(dataRDD2) val dataRDDUn = dataRDD1.union(dataRDD2) val dataRDDSu: RDD [Int ] = dataRDD1.subtract(dataRDD2) val dataRDDZip = dataRDD1.zip(dataRDD2) println(dataRDDZip.collect().mkString("," )) sc.stop() } }
partitionBy
Spark的分区器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner , SparkConf , SparkContext }object Spark12_RDD_Operator_Transform_partitionBy def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [(Int , String )] = sc.makeRDD(Array ((1 ,"aaa" ),(2 ,"bbb" ),(3 ,"ccc" ),(4 ,"DDD" )),2 ) rdd.partitionBy(new HashPartitioner (2 )).saveAsTextFile("output" ) sc.stop() } }
reduceByKey
最开始在WordCount就有用到,元组聚合 相同key聚合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner , SparkConf , SparkContext }object Spark13_RDD_Operator_Transform_reduceByKey def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd = sc.makeRDD(List ( ("a" ,1 ),("a" ,2 ),("a" ,3 ),("b" ,3 ) )) val rddKey: RDD [(String , Int )] = rdd.reduceByKey((_: Int ) + (_: Int )) println(rddKey.collect().mkString("," )) sc.stop() } }
groupByKey
分组将数据源的数据根据 key 对 value 进行分组
返回值第一个是key 第二个是元组,元组内是相同key的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark14_RDD_Operator_Transform_groupByKey def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd = sc.makeRDD(List ( ("a" ,1 ),("a" ,2 ),("a" ,3 ),("b" ,3 ) )) val rddKey1 = rdd.groupBy(_._1) val rddKey = rdd.groupByKey() println(rddKey.collect().mkString(" ," )) println(rddKey1.collect().mkString(" ," )) sc.stop() } }
reduceByKey 和 groupByKey 的区别
reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用 groupByKey
aggregateByKey
将数据根据不同的规则进行分区内计算和分区间计算
两个分区先取最大值 (a,2)(c,3) + (a,5)(c,6)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD .rddToPairRDDFunctionsimport org.apache.spark.{SparkConf , SparkContext }object Spark15_RDD_Operator_Transform_aggregateByKey def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd = { sc.makeRDD(List ( ("a" ,1 ),("a" ,2 ),("c" ,3 ), ("c" ,4 ),("a" ,5 ),("c" ,6 ) ),2 ) } rdd.aggregateByKey(0 )( (x, y) => math.max(x, y), (x, y) => x + y ).collect().foreach(println) sc.stop() } }
foldByKey
当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
两边分区相同key先加 加完分区间key加
1 2 val dataRDD1 = sparkContext.makeRDD(List (("a" ,1 ),("b" ,2 ),("c" ,3 )))val dataRDD2 = dataRDD1.foldByKey(0 )(_+_)
combineByKey
最通用的对 key-value 型 rdd 进行聚集操作的聚集函数
允许用户返回值的类型与输入不一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.rdd.RDD .rddToPairRDDFunctionsimport org.apache.spark.{SparkConf , SparkContext }object Spark16_RDD_Operator_Transform_combineByKey def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd = { sc.makeRDD(List ( ("a" ,1 ),("a" ,2 ),("b" ,3 ), ("b" ,4 ),("b" ,5 ),("a" ,6 ) ),2 ) } val newRDD: RDD [(String , (Int , Int ))] = rdd.combineByKey( (v: Int ) => (v, 1 ), (x: (Int , Int ), y: Int ) => { (x._1 + y, x._2 + 1 ) }, (t1: (Int , Int ), t2: (Int , Int )) => { (t1._1 + t2._1, t1._2 + t2._2) } ) val resultRDD: RDD [(String , Int )] = newRDD.mapValues { case (num, count) => num / count } println(newRDD.collect().mkString(" ," )) println(resultRDD.collect().mkString("," )) sc.stop() } }
sortByKey
在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口(特质),返回一个按照 key 进行排序
上限比较高 可以自定义类 当作key
1 2 3 val dataRDD1 = sparkContext.makeRDD(List (("a" ,1 ),("b" ,2 ),("c" ,3 )))val sortRDD1: RDD [(String , Int )] = dataRDD1.sortByKey(true )val sortRDD1: RDD [(String , Int )] = dataRDD1.sortByKey(false )
join
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的(K,(V,W))的 RDD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.rdd.RDD .rddToPairRDDFunctionsimport org.apache.spark.{SparkConf , SparkContext }object Spark17_RDD_Operator_Transform_join def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [(String , Int )] = sc.makeRDD(List (("a" ,1 ),("b" ,2 ),("c" ,3 ))) val rdd1: RDD [(String , Int )] = sc.makeRDD(List (("b" ,4 ),("a" ,5 ),("c" ,3 ))) val joinRDD: RDD [(String , (Int , Int ))] = rdd.join(rdd1) joinRDD.mapValues{ case (x,y) => x+y }.collect().foreach(println) joinRDD.collect().foreach(println) sc.stop() } }
cogroup
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable,Iterable))类型的 RDD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.rdd.RDD .rddToPairRDDFunctionsimport org.apache.spark.{SparkConf , SparkContext }object Spark18_RDD_Operator_Transform_cogroup def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [(String , Int )] = sc.makeRDD(List (("a" ,1 ),("b" ,2 ))) val rdd1: RDD [(String , Int )] = sc.makeRDD(List (("b" ,4 ),("a" ,5 ),("c" ,3 ),("c" ,6 ))) val rdd2: RDD [(String , Int )] = sc.makeRDD(List (("c" ,4 ),("e" ,5 ),("a" ,3 ),("a" ,6 ))) rdd.cogroup(rdd1,rdd2).collect().foreach(println) sc.stop() } }
leftOuterJoin
类似于 SQL 语句的左外连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package BIgDataSparkDay2 import org.apache.spark.rdd.RDD import org.apache.spark.rdd.RDD .rddToPairRDDFunctionsimport org.apache.spark.{SparkConf , SparkContext }object Spark19_RDD_Operator_Transform_leftOuterJoin def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd1: RDD [(String , Int )] = sc.makeRDD(List (("b" ,4 ),("a" ,5 ),("c" ,3 ))) val rdd2: RDD [(String , Int )] = sc.makeRDD(List (("b" ,3 ),("a" ,2 ),("c" ,6 ))) rdd1.leftOuterJoin(rdd2).collect().foreach(println) sc.stop() } }
5.BUG点
在RDD操作中有一项拉链操作,就是将两组集合变成key-Vlaue类型的,在Scala中,如果两组数据不一样长,Vlaue会变成默认值,但是在RDD中我就出现了报错,报错信息说两组RDD值长度要一样。
6.扩展学习部分
用Spark读取文件 一行一行 并用map读取路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package BIgDataSparkDay2 import org.apache.spark.{SparkConf , SparkContext }object Spark01_RDD_Operator_Transform_Test def main Array [String ]): Unit = { val sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val text = sc.textFile("datas/apache.log" ) val value = text.map( (line: String ) =>{ val strings: Array [String ] = line.split(" " ) strings(6 ) } ) value.collect().foreach(println) sc.stop() } }
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的学习内容是算法方面的,Spark独有的,转换算子,将scala中的优秀特质结合,把RDD中的数据做各种各样的处理,有25个左右的方法,单Value和双Value的都有,难度是很大的,偏向算法,比之前的scala集合的高阶还难不少,想搞定这个还得在去看一下scala集合的高阶方法,元组方面用的比较多,这样能让代码很简洁,自己去CSDN搜了scala的自动类型补全,这样理解起来比之前好了很多。掌握程度70%,因为在赶进度,有些小案例没去敲,更多是自己的理解,结合文档的讲解。方法太多了,也不是很能记住,还是得等案例的时候,能上场使用一下,这样对自己理解有很大的帮助。
7.23 Spark-RDD完结
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 081 Core - 核心编程 - RDD - 行动算子 - 介绍082 Core - 核心编程 - RDD - 行动算子 - 算子演示083 Core - 核心编程 - RDD - 行动算子 - aggregate084 Core - 核心编程 - RDD - 行动算子 - countByKey & countByValue 085 Core - 核心编程 - RDD - WordCount不同的实现方式 - (1 -8 )086 Core - 核心编程 - RDD - WordCount不同的实现方式 - (9 -11 )087 Core - 核心编程 - RDD - 行动算子 - save的方法088 Core - 核心编程 - RDD - 行动算子 - foreach089 Core - 核心编程 - RDD - 序列化 - 闭包检测090 Core - 核心编程 - RDD - 序列化 - 实际执行时的问题091 Core - 核心编程 - RDD - 序列化 - Kryo序列化Core介绍092 Core - 核心编程 - RDD - 依赖关系 - 依赖 & 血缘关系介绍 093 Core - 核心编程 - RDD - 依赖关系 - 血缘关系 - 演示094 Core - 核心编程 - RDD - 依赖关系 - 宽窄依赖095 Core - 核心编程 - RDD - 依赖关系 - 阶段&分区&任务 - 概念解析 - 秋游了 096 Core - 核心编程 - RDD - 依赖关系 - 阶段划分源码解读097 Core - 核心编程 - RDD - 依赖关系 - 任务划分源码解读098 Core - 核心编程 - RDD - 依赖关系 - 任务分类099 Core - 核心编程 - RDD - 持久化 - cache & persist基本原理和演示 100 Core - 核心编程 - RDD - 持久化 - 作用101 Core - 核心编程 - RDD - 持久化 - 检查点102 Core - 核心编程 - RDD - 持久化 - 区别
3.所学内容概述
行动算子
序列化
依赖关系
持久化
4.根据概述分章节描述
RDD行动算子
行动算子就是触发作业(job)执行的方法
reduce
以及基本简单方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package BIgDataSparkDay3 .actionimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark02_RDD_Operator_reduce def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [Int ] = sc.makeRDD(List (1 , 4 , 3 , 2 )) val i: Int = rdd.reduce((_: Int ) + (_: Int )) println(i) val ints: Array [Int ] = rdd.collect() println(ints.mkString("," )) val countResult: Long = rdd.count() println(countResult) println(rdd.first()) val ints1: Array [Int ] = rdd.take(3 ) println(ints1.mkString("," )) val ints2: Array [Int ] = rdd.takeOrdered(3 ) println(ints2.mkString("," )) sc.stop() } }
collect
在驱动程序中,以数组 Array 的形式返回数据集的所有元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package BIgDataSparkDay3 .actionimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark01_RDD_Operator_Action def main Array [String ]): Unit = { val sparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [Int ] = sc.makeRDD(List (1 , 2 , 3 , 4 )) rdd.collect() sc.stop() } }
aggregate & fold
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package BIgDataSparkDay3 .actionimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark03_RDD_Operator_aggregate def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [Int ] = sc.makeRDD(List (1 , 4 , 3 , 2 ),2 ) val result1: Int = rdd.aggregate(0 )(_ + _, _ + _) val result2: Int = rdd.aggregate(10 )(_ + _, _ + _) println(result1) println(result2) val foldResult1: Int = rdd.fold(0 )(_+_) val foldResult2: Int = rdd.fold(10 )(_+_) println(foldResult1) println(foldResult2) sc.stop() } }
countByKey & countByValue
统计每种 key 的个数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package BIgDataSparkDay3 .actionimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark04_RDD_Operator_countByKey def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [(Int , String )] = sc.makeRDD(List ((1 , "a" ), (1 , "a" ), (1 , "a" ), (2 , "b" ), (3 , "c" ), (3 , "c" ))) val resultKey: collection.Map [Int , Long ] = rdd.countByKey() val resultValue: collection.Map [(Int , String ), Long ] = rdd.countByValue() println(resultKey) println(resultValue) sc.stop() } }
save相关算子
保存文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package BIgDataSparkDay3 .actionimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark05_RDD_Operator_Save def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [(Int , String )] = sc.makeRDD(List ((1 , "a" ), (1 , "a" ), (1 , "a" ), (2 , "b" ), (3 , "c" ), (3 , "c" ))) rdd.saveAsTextFile("output" ) rdd.saveAsObjectFile("output1" ) rdd.saveAsSequenceFile("output2" ) sc.stop() } }
foreach
分布式遍历 RDD 中的每一个元素,调用指定函数 下文有行动算子的执行原理解释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package BIgDataSparkDay3 .actionimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark06_RDD_Operator_Foreach def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("Operator" ) val sc = new SparkContext (sparkConf) val rdd: RDD [Int ] = sc.makeRDD(List (1 ,2 ,3 ,4 )) rdd.collect().foreach(println) println("****************" ) rdd.foreach(println) sc.stop() } }
RDD序列化
算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行
要清晰上面这句话,Scala是函数式编程,,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor端执行,就会发生错误。所以要解决算子使用算子外数据的问题,就需要数据序列化。
java中序列化是继承Serializable,在scala中称之为混入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package BIgDataSparkDay3 .serialimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark01_RDD_Serial def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setMaster("local" ).setAppName("WordCount" ) val sc = new SparkContext (conf) val rdd: RDD [String ] = sc.makeRDD(Array ("hello world" , "hello spark" , "hive" , "atguigu" )) val search = new Search ("h" ) search.getMatch2(rdd).collect().foreach(println) sc.stop() } class Search (query:String ) extends Serializable def isMatch String ): Boolean = { s.contains(query) } def getMatch1 RDD [String ]): RDD [String ] = { rdd.filter(isMatch) } def getMatch2 RDD [String ]): RDD [String ] = { rdd.filter((x: String ) => x.contains(query)) } } }
RDD依赖关系
依赖关系,其实就是两个相邻 RDD 之间的关系 和java中的子类父类差不多吧
RDD的持久化
RDD代码,很长一些是重复的,如果使用不同是行动算子,会重新调用一遍之前的代码,这样效率太低了。
持久化可以将之前的依赖和代码保存在临时文件或者磁盘中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package BIgDataSparkDay3 .persistimport org.apache.spark.rdd.RDD import org.apache.spark.storage.StorageLevel import org.apache.spark.{SPARK_BRANCH , SparkConf , SparkContext }object Spark01_RDD_Persist def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local" ).setAppName("Persist" ) val sc = new SparkContext (sparkConf) val list = List ("Hello Scala" , "Hello Spark" ) val rdd:RDD [String ] = sc.makeRDD(list) val flatRDD: RDD [String ] = rdd.flatMap((_:String ).split(" " )) val mapRDD: RDD [(String , Int )] = flatRDD.map( (word: String ) => { println("@@@@@@@@@@@@@@@@@" ) (word,1 ) } ) mapRDD.persist(StorageLevel .DISK_ONLY ) val reduceRDD: RDD [(String , Int )] = mapRDD.reduceByKey((_:Int ) + (_:Int )) val reduceRDD1: RDD [(String , Iterable [Int ])] = mapRDD.groupByKey() reduceRDD.collect().foreach(println) println("————————————————————————————————————" ) reduceRDD1.collect().foreach(println) sc.stop() } }
checkpoint的使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package BIgDataSparkDay3 .persistimport org.apache.spark.rdd.RDD import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf , SparkContext }object Spark02_RDD_Persist def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local" ).setAppName("Persist" ) val sc = new SparkContext (sparkConf) sc.setCheckpointDir("cp" ) val list = List ("Hello Scala" , "Hello Spark" ) val rdd:RDD [String ] = sc.makeRDD(list) val flatRDD: RDD [String ] = rdd.flatMap((_:String ).split(" " )) val mapRDD: RDD [(String , Int )] = flatRDD.map( (word: String ) => { println("@@@@@@@@@@@@@@@@@" ) (word,1 ) } ) mapRDD.cache() mapRDD.checkpoint() val reduceRDD: RDD [(String , Int )] = mapRDD.reduceByKey((_:Int ) + (_:Int )) val reduceRDD1: RDD [(String , Iterable [Int ])] = mapRDD.groupByKey() reduceRDD.collect().foreach(println) println("————————————————————————————————————" ) reduceRDD1.collect().foreach(println) sc.stop() } }
持久化几种方式的区别
分区器
➢ 只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 None
之前使用过repartition 是hash分区 现在可以自定义分区
分区类 要继承 Partitioner
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package WordCount import org.apache.spark.rdd.RDD import org.apache.spark.{Partitioner , SparkConf , SparkContext }object Spark03_RDD_repartition def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local" ).setAppName("Persist" ) val sc = new SparkContext (sparkConf) val list = List (("NBA" ,1 ),("CBA" ,2 ),("WNBA" ,3 ),("CUBA" ,4 )) val rdd: RDD [(String , Int )] = sc.makeRDD(list, 3 ) val value: RDD [(String , Int )] = rdd.partitionBy(new MyPartitioner ) value.saveAsTextFile("output" ) sc.stop() } class MyPartitioner extends Partitioner override def numPartitions Int = 3 override def getPartition Any ): Int = { key match { case "NBA" => 0 case "CBA" => 1 case _ => 2 } } } }
累加器
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。
像Range使用的时候就不会传回到Driver端 Driver传到Executor端以后,在Executor端做任务,不会传回Driver端
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package BIgDataSparkDay3 .addimport org.apache.spark.rdd.RDD import org.apache.spark.util.LongAccumulator import org.apache.spark.{SparkConf , SparkContext }object Spark01_RDD_add def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("add" ) val sc = new SparkContext (sparkConf) val rdd: RDD [Int ] = sc.makeRDD(List (1 ,2 ,3 ,4 ,5 )) val sum: LongAccumulator = sc.longAccumulator("sum2" ) rdd.foreach( (num: Int ) => { sum.add(num) } ) println("sum = " + sum.value) sc.stop() } }
5. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
执行自定义分区器的时候,报了一大串的错误,一个一个翻译过来,有一个错误是指向了自己自定义类的case表达式,检查过后发现,自己有四个Key-value,3个分区,按照索引下标 0 1 2 ,所以后面自己自定义match类应该返回三个值,而且key值得都有返回值。所以按自己的写法,会有一个键值对没有返回值,也就没有分区导致报错。把最后一个改成 case _ => 2表示除了前两个之外,返回值都是分区2
6.扩展学习部分
Kryo 序列化框架
scala所独有的,java中序列化的升级版,性能大大提高。
Kryo 速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化。
注意:即使使用 Kryo 序列化,也要继承 Serializable 接口。代码量会增加一点,但是效率大大提高
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package BIgDataSparkDay3 .serialimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark02_RDD_SerialKryo def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setMaster("local" ).setAppName("WordCount" ) .set("spark.serializer" , "org.apache.spark.serializer.KryoSerializer" ) .registerKryoClasses(Array (classOf[Search ])) val sc = new SparkContext (conf) val rdd: RDD [String ] = sc.makeRDD(Array ("hello world" , "hello spark" , "hive" , "atguigu" )) val search = new Search ("h" ) search.getMatch2(rdd).collect().foreach(println) sc.stop() } case class Search (query:String ) def isMatch String ): Boolean = { s.contains(query) } def getMatch1 RDD [String ]): RDD [String ] = { rdd.filter(isMatch) } def getMatch2 RDD [String ]): RDD [String ] = { rdd.filter((x: String ) => x.contains(query)) } } }
RDD 任务划分 RDD 任务切分中间分为:Application、Job、Stage 和 Task
Application:初始化一个 SparkContext 即生成一个 Application;
Job:一个 Action 算子就会生成一个 Job;
Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的学习内容和难度都是有点大的,前面先学的行动算子,比较简单,和昨天的转换算子差不多,比转换算子的算法还简单不少,但是代码比较多的,也是今天学习的重点,敲了一上午才结束行动算子,做了小案例。后面下午,精神状态还不错,看到序列化 依赖 持久之类的,在Java中都有点类似的东西,加上老师的画图理解,自己结合案例,也是弄得明白个八九十了。学习步骤,因为文档没有讲解,就看了视频,案例自己敲,没什么问题就跳着看老师的运行,看和自己有什么不一样,明天就是SQL的学习了。代码应该也比较多,还要记SQL语句的。
7.24 Spark SQL
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 153 SQL - 介绍154 SQL - 特点155 SQL - 数据模型 - DataFrame & DataSet156 SQL - 核心编程 - DataFrame - 简单演示157 SQL - 核心编程 - DataFrame - SQL的基本使用158 SQL - 核心编程 - DataFrame - DSL语法的基本使用159 SQL - 核心编程 - DataFrame - RDD之间的转换160 SQL - 核心编程 - DataSet - 介绍161 SQL - 核心编程 - DataSet - DataFrame的转换162 SQL - 核心编程 - DataSet - RDD的转换163 SQL - 核心编程 - DataSet & DataFrame & RDD之间的关系164 SQL - 核心编程 - IDEA创建SparkSQL环境对象165 SQL - 核心编程 - IDEA - DataFrame基本操作166 SQL - 核心编程 - IDEA - DataSet基本操作167 SQL - 核心编程 - IDEA - RDD & DataFrame & DataSet互相转换168 SQL - 核心编程 - IDEA - UDF函数169 SQL - 核心编程 - IDEA - UDAF函数 - 实现原理170 SQL - 核心编程 - IDEA - UDAF函数 - 弱类型函数实现171 .尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 强类型函数实现172 .尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 早期强类型函数实现173 .尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 课件梳理174 .尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 通用方法175 .尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作JSON & CSV176 .尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作MySQL177 .尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作内置Hive178 .尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作外置Hive179 .尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 代码操作外置Hive180 .尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - beeline操作Hive181 .尚硅谷_SparkSQL - 案例实操 - 数据准备182 .尚硅谷_SparkSQL - 案例实操 - 需求部分实现183 .尚硅谷_SparkSQL - 案例实操 - 需求完整实现184 .尚硅谷_SparkSQL - 总结 - 课件梳理
3.所学内容概述
4.根据概述分章节描述
SparkSQL概述
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
对于开发人员来讲,SparkSQL 可以简化 RDD 的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采的就是 SparkSQL。Spark SQL 为了简化 RDD 的开发,提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的 RDD
➢ DataFrame
➢ DataSet
SparkSQL 特点1 2 3 4 易整合:无缝的整合了 SQL 查询和 Spark 编程 统一的数据访问:使用相同的方式。连接不同的数据源 兼容Hive:在已有的仓库上直接运行SQL 或者 HIveQL. 标准数据连接:通过JDBC或者ODBC来连接
DataFrame是什么
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格。
下图直观地体现了 DataFrame 和 RDD 的区别。 DataFrame每一列都带有名称和类型
DataSet 是什么
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame的一个扩展。
用编程的话说就是DataSet是DataFrame的子类,升级版。DataFrame拥有的功能DataSet都有。
SparkSQL的核心编程
DataFrame
Spark SQL 的 DataFrame API 允许我们使用 DataFrame 而不用必须去注册临时表或者生成 SQL 表达式。DataFrame API 既有 transformation 操作也有 action 操作。
创建DataFrame
1.从Spark数据源进行创建
1 2 3 scala > spark.read. csv format jdbc json load option options orc parquet schema table text textFile
读取json创建DataFrame
1 2 scala> val df = spark.read.json("data/user.json" ) df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
1 2 3 4 5 +---+--------+ |age|username| +---+--------+ | 20 |zhangsan| +---+--------+
2.用SQL语法
对 DataFrame 创建一个临时表
1 scala> df.createOrReplaceTempView("people" )
通过 SQL 语句实现查询全表
1 2 scala> val sqlDF = spark.sql("SELECT * FROM people") sqlDF: org.apache.spark.sql.DataFrame = [age : bigint , name : string ]
show进行一个输出
1 2 3 4 5 6 7 8 scala> sqlDF.show +---+--------+ |age|username| +---+--------+ | 20 |zhangsan| | 30 | lisi| | 40 | wangwu| +---+--------+
DSL语法
DataFrame 提供一个特定领域语言去管理结构化的数据。可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了。
只查看"username"列数据
1 2 3 4 5 6 7 8 scala> df.select("username").show() +--------+ |username| +--------+ |zhangsan| | lisi| | wangwu| +--------+
查看"username"列数据以及"age+1"数据
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
1 2 scala> df.select($"username" ,$"age" + 1 ).show scala> df.select('username, 'age + 1 ).show()
DataFrame可以用很多RDD的方法 filter group等
IDEA开发SparkSQL
实际开发中,都是使用 IDEA 进行开发的。
要添加XML依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-core_2.12</artifactId > <version > 3.0.0</version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-sql_2.12</artifactId > <version > 3.0.0</version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-yarn_2.12</artifactId > <version > 3.0.0</version > </dependency >
之前CMD敲的代码在IDEA实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 package SQL import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame , Dataset , Row , SparkSession }import org.apache.spark.{SparkConf , SparkContext }object Spark01_SparkSQL_Basic def main Array [String ]): Unit = { val sparkSQL: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("SparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkSQL).getOrCreate() import spark.implicits._ val context: SparkContext = spark.sparkContext val rdd: RDD [(Int , String , Int )] = context.makeRDD(List ((1 , "zhangsan" , 30 ), (2 , "lisa" , 40 ))) val df: DataFrame = rdd.toDF("id" , "name" , "age" ) val rowRDD: RDD [Row ] = df.rdd val ds: Dataset [User ] = df.as[User ] val df1: DataFrame = ds.toDF() val ds1: Dataset [User ] = rdd.map { case (id, name, age) => User (id, name, age) }.toDS() val userRDD: RDD [User ] = ds1.rdd spark.stop() } case class User (id:Int ,username:String ,age:Int ) }
用户自定义函数
用户可以通过 spark.udf 功能添加自定义函数,实现自定义功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package SQL import org.apache.spark.sql.{DataFrame , Dataset , Row , SparkSession }import org.apache.spark.{SparkConf , SparkContext }object Spark02_SparkSQL_UDF def main Array [String ]): Unit = { val sparkSQL: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("SparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkSQL).getOrCreate() import spark.implicits._ val df: DataFrame = spark.read.json("data/user.json" ) df.createOrReplaceTempView("user" ) spark.udf.register("prefixName" ,(name:String ) => "姓名: " + name) spark.sql("select * from user" ).show() spark.stop() } case class User (id:Int ,username:String ,age:Int ) }
UDAF
是Spark3.0后面出现的自定义强类型聚合函数Aggreg 代替原来的弱类型的聚合函数UserDefinedAggregateFunction
计算平均工资
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 package SQL import org.apache.spark.SparkConf import org.apache.spark.sql.expressions.Aggregator import org.apache.spark.sql._object Spark04_SparkSQL_UDAF1 def main Array [String ]): Unit = { val sparkSQL: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("SparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkSQL).getOrCreate() val df: DataFrame = spark.read.json("data/user.json" ) df.createOrReplaceTempView("user" ) spark.udf.register("ageAvg" ,functions.udaf(new MyAvgUDAF ())) spark.sql("select ageAvg(age) from user" ).show() spark.stop() } case class ByMyBuff (var total: Long ,var count: Long ) class MyAvgUDAF extends Aggregator [Long ,ByMyBuff ,Long ] override def zero ByMyBuff = { ByMyBuff (0 L,0 L) } override def reduce ByMyBuff , a: Long ): ByMyBuff = { b.total = b.total + a b.count = b.count + 1 b } override def merge ByMyBuff , b2: ByMyBuff ): ByMyBuff = { b1.total = b1.total + b2.total b1.count = b1.count + b2.count b1 } override def finish ByMyBuff ): Long = { reduction.total / reduction.count } override def bufferEncoder Encoder [ByMyBuff ] = Encoders .product override def outputEncoder Encoder [Long ] = Encoders .scalaLong } }
数据的加载和保存
SparkSQL 提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL 默认读取和保存的文件格式为 parquet
1 2 3 4 spark.read.load 是加载数据的通用方法 scala> spark.read.format ("…")[.option("…")].load("…") df.write.save 是保存数据的通用方法 scala>df.write.format ("…")[.option("…")].save("…")
➢ format(“…”):指定加载的数据类型,包括"csv"、“jdbc”、“json”、“orc”、“parquet"和"textFile”。
➢ load(“…”):在"csv"、“jdbc”、“json”、“orc”、"parquet"和"textFile"格式下需要传入加载数据的路径。
➢ option(“…”):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
加载MySQL数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package SQL .MySQL import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame , SparkSession }object Spark01_SparkSQL_MySQL def main Array [String ]): Unit = { val sparkSQL: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("SparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkSQL).getOrCreate() import spark.implicits._ spark.read .format("jdbc" ) .option("url" , "jdbc:mysql://localhost:3306/atguigudb?rewriteBatchedStatements=true" ) .option("driverClass" , "com.mysql.cj.jdbc.Drive" ) .option("user" , "root" ) .option("password" , "root" ) .option("dbtable" , "employees" ) .load().show spark.stop() } case class User (id:Int ,username:String ,age:Int ) }
5. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
错误点如图,显而易见又是路径问题,同样的代我之前是在Spark下载文件直接打开Spark-shell使用的,之前是好的,因为太麻烦,所以设置了环境变量,在任何地方输入spark-shell都能打开spark,但是这样我输之前的路径就不行了,必须要绝对路径,不知道原因
RDD、DataFrame、DataSet 三者的关系
因为是在文档中看的 基本都是文字性的描述
版本出现的时间
➢ Spark1.0 => RDD
➢ Spark1.3 => DataFrame
➢ Spark1.6 => Dataset
时代是在进步的,所以看出现版本就知道哪个更加强大,所以DataSet也是现在的主流
在后期的 Spark 版本中,DataSet 有可能会逐步取代 RDD和 DataFrame 成为唯一的 API 接口。
三者的共性
➢ RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数据提供便利;
➢ 三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到Action 如 foreach 时,三者才会开始遍历运算;
➢ 三者有许多共同的函数,如 filter,排序等;
➢ 在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:import spark.implicits._(在创建好 SparkSession 对象后尽量直接导入)
➢ 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
➢ 三者都有 partition 的概念
➢ DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
DataSet
DataSet
➢ Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
➢ DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共性中的第七条提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息
三者是可以互相转换的 通过特定方式
具体代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 package SQL import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame , Dataset , Row , SparkSession }import org.apache.spark.{SparkConf , SparkContext }object Spark01_SparkSQL_Basic def main Array [String ]): Unit = { val sparkSQL: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("SparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkSQL).getOrCreate() import spark.implicits._ val context: SparkContext = spark.sparkContext val rdd: RDD [(Int , String , Int )] = context.makeRDD(List ((1 , "zhangsan" , 30 ), (2 , "lisa" , 40 ))) val df: DataFrame = rdd.toDF("id" , "name" , "age" ) val rowRDD: RDD [Row ] = df.rdd val ds: Dataset [User ] = df.as[User ] val df1: DataFrame = ds.toDF() val ds1: Dataset [User ] = rdd.map { case (id, name, age) => User (id, name, age) }.toDS() val userRDD: RDD [User ] = ds1.rdd spark.stop() } case class User (id:Int ,username:String ,age:Int ) }
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的学习内容还是很重的,把SparkSQL看完,内容概念性的太多了,花费了很多时间去理解,弄懂,像搞懂RDD,DataFrame和DataSet三者就花费了2个多小时,比较麻烦,前面cmd执行出了点问题,好在解决了,但是没弄懂原因。重点在DataSet的使用和几个自定义方法吧,DataSet应该是现在开发最常用的,这部分我也花重点时间去掌握了,其他一些抽象的概念简单过了一下,有些是对Hive的操作,因为Hive还没写,就没看,明天学Hive了,后面再回来把对Hive操作的这几集看了。
7.27 Hive 配置以及DDL语句
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 P1001-尚硅谷-Hive-课程介绍 P2002-尚硅谷-Hive-概念介绍- P3003-尚硅谷-Hive-优缺点 P4004-尚硅谷-Hive-架构 P5005-尚硅谷-Hive-与数据库比较 P6006-尚硅谷-Hive-安装&启动 P7007-尚硅谷-Hive-简单使用&Derby存储元数据的问题 P8008-尚硅谷-Hive-MySQL的安装&启动 P9009-尚硅谷-Hive-配置Hive元数据存储为MySQL&再次启动测试 P10010-尚硅谷-Hive-使用元数据服务的方式访问Hive P11011-尚硅谷-Hive-使用JDBC的方式访问Hive P12012-尚硅谷-Hive-元数据服务&Hiveserver2脚本封装 P13013-尚硅谷-Hive-修改配置文件使用直连方式访问Hive P14014-尚硅谷-Hive-其他交互方式 P15015-尚硅谷-Hive-配置日志文件位置&打印当前库名&表头信息 P16016-尚硅谷-Hive-配置信息位置&优先级 P17017-尚硅谷-Hive-课程回顾 P18018-尚硅谷-Hive-关于count star不执行MR任务的说明 P19019-尚硅谷-Hive-Hive中数据类型 一 P20020-尚硅谷-Hive-Hive中数据类型 二 P21021-尚硅谷-Hive-DDL 创建数据库 P22022-尚硅谷-Hive-DDL 查询&切换数据库 P23023-尚硅谷-Hive-DDL 修改&删除数据库 P24024-尚硅谷-Hive-DDL 建表语句分析 P25025-尚硅谷-Hive-DDL 内外部创建&区别 P26026-尚硅谷-Hive-DDL 内外部互相转换 P27027-尚硅谷-Hive-DDL 建表时指定字段分隔符 P28028-尚硅谷-Hive-DDL 修改&删除表
3.所学内容概述
1-18配置Hive在Centos7
Hive数据类型
DDL操作
4.根据概述分章节描述
Hive数据类型
注意一点 时间类型 可以直接String类型yyyy-mm-dd,这样用。
对于 Hive 的 String 类型相当于数据库的 varchar 类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储 2GB 的字符数。
集合数据类型
Hive 有三种复杂数据类型 ARRAY、MAP 和 STRUCT。ARRAY 和 MAP 与 Java 中的 Array和 Map 类似,而 STRUCT 与 C 语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
案例实操
创建本地测试文件 test.txt
1 2 songsong,bingbing_lili,xiao song:18 _xiaoxiao song:19 ,hui long guan_beijing yangyang,caicai_susu,xiao yang:18 _xiaoxiao yang:19 ,chao yang_beijing
Hive 上创建测试表 test
1 2 3 4 5 6 7 8 9 create table test( name string, friends array<string>, children map<string, int>, address struct<street:string, city:string> ) row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' lines terminated by '\n';
后面四个字段的解释
1 2 3 4 row format delimited fields terminated by ',' -- 列分隔符 collection items terminated by '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号) map keys terminated by ':' -- MAP 中的 key 与 value 的分隔符 lines terminated by '\n'; -- 行分隔符
DDL数据定义
创建数据库 1 create database if not exists db_hive; #增加 if not exists 判断
指定数据库在 HDFS 上存放的位置
1 create database db_hive2 location '/db_hive2.db' ;
查询数据库 切换当前数据库
1 hive (default)> use db_hive;
修改数据库
用户可以使用 ALTER DATABASE 命令为某个数据库的 DBPROPERTIES 设置键-值对属性值,来描述这个数据库的属性信息。
1 2 hive (default)> alter database db_hive set dbproperties('createtime'='20170830');
删除数据库
1 2 3 hvie>drop database db_hive2; //删除空的数据库 hive> drop database if exists db_hive2; //判断数据库是否存在 hive> drop database db_hive cascade; //强制删除数据库 不管是否为空
创建表 建表语法
1 2 3 4 5 6 7 8 9 10 11 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_
1 2 3 4 5 6 (1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。 (2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。 (3)COMMENT:为表和列添加注释。 (4)PARTITIONED BY 创建分区表 (5)CLUSTERED BY 创建分桶表 (6)SORTED BY 不常用,对桶中的一个或多个列另外排序
实操案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 (1)查询表结构 hive> desc dept; (2)添加列 hive (default)> alter table dept add columns(deptdesc string); (3)查询表结构 hive> desc dept; (4)更新列 hive (default)> alter table dept change column deptdesc desc string; (5)查询表结构 hive> desc dept; (6)替换列 hive (default)> alter table dept replace columns(deptno string, dname string, loc string); (7)查询表结构 hive> desc dept;
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
前天和昨天基本配置了一天的hive,第一天自己配置和yzg帮我一起弄的,后面jar包找不到了,第二天自己又建了一组克隆机,然而配置到JDBC的时候又出现了问题,等了20分钟都没启动起来。后面干脆不管了,就跳过去了,JDBC的部分,因为后面都是直连使用的,就直接看过去了。等部署的同学搞好帮我配一台,Hive的数据类型和Java基本一样就是Long变成了BIGINT,DDL的操作也和MySQL差不多,创建表稍微有点繁琐。语法有很多的字段代码不太好记,DDL似乎不太重要,后面用到的时候,语法敲着敲着就熟悉了,明天学DML了。
7.28 DML操作
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 P29029-尚硅谷-Hive-DML 加载数据 load P30030-尚硅谷-Hive-DML 加载数据 insert P31031-尚硅谷-Hive-DML 加载数据 as select P32032-尚硅谷-Hive-DML 加载数据 location P33033-尚硅谷-Hive-DML 加载数据 import 未完待续 P34034-尚硅谷-Hive-DML 导出数据 insert P35035-尚硅谷-Hive-DML 导出数据 hadoop命令&Hive shell P36036-尚硅谷-Hive-DML 导出数据 export&sqoop说明 import 补充 P37037-尚硅谷-Hive-DML 清空全表 P38038-尚硅谷-Hive-DML 查询 准备数据 P39039-尚硅谷-Hive-DML 查询 查询全表&指定列 注意事项 P40040-尚硅谷-Hive-DML 查询 列别名&运算符 P41041-尚硅谷-Hive-DML 查询 聚合函数&Limit &Where P42042-尚硅谷-Hive-DML 查询 比较运算符&逻辑运算符 P43043-尚硅谷-Hive-DML 查询 GroupBy & Having P44044-尚硅谷-Hive-课程回顾 P45045-尚硅谷-Hive-DML 查询 JOIN 内连接 P46046-尚硅谷-Hive-DML 查询 JOIN 左外连接 P47047-尚硅谷-Hive-DML 查询 JOIN 右外连接 P48048-尚硅谷-Hive-DML 查询 JOIN 满外连接 P49049-尚硅谷-Hive-DML 查询 JOIN 取左表独有数据 P50050-尚硅谷-Hive-DML 查询 JOIN 取右表独有数据 P51051-尚硅谷-Hive-DML 查询 JOIN 取左右两表独有数据 P52052-尚硅谷-Hive-DML 查询 JOIN 多表连接 P53053-尚硅谷-Hive-DML 查询 JOIN 笛卡尔积 P54054-尚硅谷-Hive-DML 查询 排序 Order By P55055-尚硅谷-Hive-DML 查询 排序 Sort By P56056-尚硅谷-Hive-DML 查询 排序 Distribute By & Cluster By P57057-尚硅谷-Hive-DML 查询 排序 4 个By 总结
3.所学内容概述
数据导入
数据导出
查询!
4.根据概述分章节描述
数据导入
向表中装载数据(Load)
1 2 hive> load data [local] inpath '数据的 path' [overwrite] into table student [partit555555
案例
1 2 3 hive (default)> create table student(id string, name string) row format delimited fields terminated by ','; //创建一张表 hive(default)> lcoal data local inpath './student.txt' into table default.student;
通过查询语句向表中插入数据(Insert )1 2 hive(default)> insert overwrite table student1 > select * from student;
查询语句中创建表并加载数据As Select
1 2 create table if not exists student3 as select id, name from student;
创建表时通过Location指定加载数据路径
1 2 3 4 hive (default)> create external table if not exists student5( id int, name string) row format delimited fields terminated by ',' location '/student;
Import 数据到指定 Hive 表中注意:先用 export 导出后,再将数据导入。
1 2 hive (default)> import table student2 from '/user/hive/warehouse/export/student';
数据导出
将查询的结果导出到本地
1 2 3 hive> insert overwrite local directory './student' //到hive/student文件夹 > row format delimited fields terminated by ',' //格式化导出 分隔符为, > select * from student5;
如果导出到HDFS 就把local 去掉 后面指定 HDFS的路径 可以直接CP 所以不常用
hadoop命令导出到本地
这个比上面的常用
Hive Shell 命令导出 基本语法:(hive -f/-e 执行语句或者脚本 > file)
缺点:打印出来有表头信息 所以不常用
1 2 [atguigu@hadoop102 hive]$ bin/hive -e 'select * from default.student;' >> /opt/module/hive/data/export/student4.txt;
**清除表中数据(**Truncate)
只能清除内部表中的数据 外部表不行
1 hive (default)> truncate table student;
基本查询
和MySQL语句一样
全表和特定列查询
1 2 select * from emp; select empno, ename from emp;
注意:
1 2 3 4 5 注意: (1 )SQL 语言大小写不敏感。 (2 )SQL 可以写在一行或者多行 (3 )关键字不能被缩写也不能分行 (4 )各子句一般要分行写。 (5 )使用缩进提高语句的可读性。
列别名
1 select ename AS name, deptno dn from emp;
AS可以不加 改成空格
算数运算符
常用函数
要通过MR 运行很慢
1 2 3 4 5 6 7 8 9 10 1)求总行数(count) hive (default)> select count(*) cnt from emp; 2)求工资的最大值(max) hive (default)> select max(sal) max_sal from emp; 3)求工资的最小值(min) hive (default)> select min(sal) min_sal from emp; 4)求工资的总和(sum) hive (default)> select sum(sal) sum_sal from emp; 5)求工资的平均值(avg) hive (default)> select avg(sal) avg_sal from emp;
Limit 语句 限制返回的行数
1 hive (default)> select * from emp limit 5; //查询EMP表 返回前5行
Where 语句 使用 WHERE 子句,将不满足条件的行过滤掉
WHERE 子句紧随 FROM 子句
1 2 3 hive (default)> select * from emp where sal >1000; --where子句不能用字段别名 --查询出薪水大于1000的所有员工
比较运算符(Between/In/ Is Null
1 2 3 4 5 6 7 8 --(1)查询出薪水等于 5000 的所有员工 hive (default)> select * from emp where sal =5000; --(2)查询工资在 500 到 1000 的员工信息 hive (default)> select * from emp where sal between 500 and 1000; --(3)查询 comm 为空的所有员工信息 hive (default)> select * from emp where comm is null; --(4)查询工资是 1500 或 5000 的员工信息 hive (default)> select * from emp where sal IN (1500, 5000);
Like 和 RLike Like和mysql中Like匹配一样,%代表零个或者多个字符(任意个字符) _代表一个字符
1 2 3 4 --(1)查找名字以 A 开头的员工信息 hive (default)> select * from emp where ename LIKE 'A%'; --(2)查找名字中第二个字母为 A 的员工信息 hive (default)> select * from emp where ename LIKE '_A%';
Rlike
RLIKE 子句是 Hive 中这个功能的一个扩展,其可以通过 Java 的正则表达式这个更强大的语言来指定匹配条件
1 2 (3)查找名字中带有 A 的员工信息 hive (default)> select * from emp where ename RLIKE '[A]';
逻辑运算符(And/Or/Not)
分组函数
分组函数的语句顺序
1 2 3 4 5 6 7 8 9 10 11 12 13 1 SELECT ... 2 FROM ... 3 WHERE ... 4 GROUP BY ... 5 HAVING ... 6 ORDER BY ...
Group By语句
计算 emp 表每个部门的平均工资
1 select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
Hiving语句
1 2 3 having 与 where 不同点(1 )where 后面不能写分组函数,而 having 后面可以使用分组函数。 (2 )having 只用于 group by 分组统计语句。
案例实操
1 2 求每个部门的平均薪水大于 2000 的部门 hive (default)> select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的DML的基本操作部分,查询语句,分组语句和SQL语句基本差不多,前面是有数据的导入和导出,是结合Hadoop以及hive自己的一些功能,可以实现本地文件或者HDFS的上传加载,导入导出。总体来说今天的学习任务不难,之前有SQL的基础,分组这边的语句,之前没学,不是很好理解,算今天的难点吧,今天学习状态还可以,敲了很多SQL语句,也都记住了,算唤醒之前SQL的记忆吧。
7.29 Join语句
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 P44044-尚硅谷-Hive-课程回顾 P45045-尚硅谷-Hive-DML 查询 JOIN 内连接 P46046-尚硅谷-Hive-DML 查询 JOIN 左外连接 P47047-尚硅谷-Hive-DML 查询 JOIN 右外连接 P48048-尚硅谷-Hive-DML 查询 JOIN 满外连接 P49049-尚硅谷-Hive-DML 查询 JOIN 取左表独有数据 P50050-尚硅谷-Hive-DML 查询 JOIN 取右表独有数据 P51051-尚硅谷-Hive-DML 查询 JOIN 取左右两表独有数据 P52052-尚硅谷-Hive-DML 查询 JOIN 多表连接 P53053-尚硅谷-Hive-DML 查询 JOIN 笛卡尔积 P54054-尚硅谷-Hive-DML 查询 排序 Order By By Distribute By & Cluster By 4 个By总结 P59059-尚硅谷-Hive-分区表 创建&简单使用 P60060-尚硅谷-Hive-分区表 分区的增删查 P61061-尚硅谷-Hive-分区表 二级分区 P62062-尚硅谷-Hive-分区表 使HDFS数据与分区表产生联系的方式 P63063-尚硅谷-Hive-分区表 load加载数据不指定分区 演示 P64064-尚硅谷-Hive-分区表 动态分区 演示 P65065-尚硅谷-Hive-分区表 动态分区 3 .0 新特性 P66066-尚硅谷-Hive-分桶表
3.所学内容概述
Join语句
查询多表
排序
4.根据概述分章节描述
等值于SQL join
Hive 支持通常的 SQL JOIN 语句。
1 2 truncate table emp;/ / 清除emp表所有行 防止用本地文件往表格内添加信息的时候 变成追加
表的别名
1 2 3 (1)好处 (1)使用别名可以简化查询。 (2)使用表名前缀可以提高执行效率。
合并员工表和部门表
1 2 hive (default)> select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno;
SQL Joins
join有很多种连接方式 都如图了 类似于集合中的交集 并集 差集
内连接 内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。 交集
1 2 hive (default)> select e.empno, e.ename, d.deptno from emp e inner join dept d on e.deptno = d.deptno;
左外连接 左外连接:JOIN 操作符左边表中符合 WHERE 子句的所有记录将会被返回。 返回join左边的表格
1 2 hive (default)> select e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno = d.deptno;
右外连接 右外连接:JOIN 操作符右边表中符合 WHERE 子句的所有记录将会被返回。 返回join右边的表格
1 2 hive (default)> select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;
满外连接 满外连接:将会返回所有表中符合 WHERE 语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用 NULL 值替代。 并集!
1 2 hive (default)> select e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno = d.deptno;
左连接
取左边特有的部分 就是左外连接除去公共部分
1 2 3 hive (default)> select e.empno, e.ename, e.deptno,d.dname from emp e left join > dept d on e.deptno = d.deptno > where d.deptno is null;
右连接和外连接类似
外连接
取两边的数据。 两表独有数据
1 2 3 hive (default)> select e.empno, e.ename, e.deptno,d.dname from emp e full join > dept d on e.deptno = d.deptno > where d.deptno is null or e.deptno is null;
查询多表
查询员工姓名(e)、部门名称(d)以及部门所在城市(l)名称;
hive运行总是从左往右
1 2 3 4 5 6 hive (default)> SELECT e.ename, d.dname, l.loc_name > FROM emp e > JOIN dept d > ON d.deptno = e.deptno > JOIN location l > ON d.loc = l.loc;
笛卡尔积
出来的行数相当于两边表格相乘
笛卡尔集会在下面条件下产生
1 2 3 (1)省略连接条件 (2)连接条件无效 (3)所有表中的所有行互相连接
案例
1 select empno, dname from emp,dept;
排序
全局排序(order by)
Order By:全局排序,只有一个 Reducer
1 2 ASC (ascend): 升序(默认)DESC (descend): 降序
案例实操
1 2 3 4 (1)查询员工信息按工资升序排列 hive (default)> select * from emp order by sal; (2)查询员工信息按工资降序排列 hive (default)> select * from emp order by sal desc;
多个列排序
1 hive (default)> select ename, deptno,sal from emp order by deptno,sal;
每个 Reduce **内部排序(**Sort By)
Sort By:对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排序,此时可以使用 **sort by**。
Sort by 为每个 reducer 产生一个排序文件。每个 Reducer 内部进行排序,对全局结果集来说不是排序 区内有序
设置 reduce 个数
1 hive (default)> set mapreduce.job.reduces=3;
根据部门编号降序查看员工信息
1 hive (default)> select * from emp sort by deptno desc;
分区**(**Distribute By)
一般和sort by一起排序
Distribute By:
在有些情况下,我们需要控制某个特定行应该到哪个 reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by 类似 MR 中 partition(自定义分区),进行分区,结合 sort by 使用。
在CSDN中有特别讲分区排序
http://t.csdn.cn/HhwIw
1 2 select * from emp distribute by deptno sort by empno desc;
部门编号分区 员工编号排序
当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式。
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序排序,不能指定排序规则为 ASC 或者 DESC
1 2 hive (default)> select * from emp cluster by deptno; hive (default)> select * from emp distribute by deptno sort by deptno;
分区表
5. BUG点
难点(关键代码或关键配置,BUG截图+解决方案)
左连接的时候,deptno这列我很多null,但是检查数据源文件这列是有的
先是怀疑hive建表的时候是不是出现了问题 又建了一遍表格发现还是有问题,查询的时候,最后一行只有null有问题
只能显示30看了自己的源文件,发现30的信息是最全的,每一列都有,就怀疑是源文件内的问题:
1 创建表格的时候分了8 列 以空格切割,但是源文件有几行 只有 6 列 7 列 那它空格切出来 也是6 列 7 列而且是按顺序。像第四列我是int 类的 但是有几行没有这一列的数据 就自动算后面的data 类型不统一 就显示了null 后面数据没有也自然显示NULL
查询hiredate的时候,发现有一行显示的5000 而这一行恰好是没有mgr的那一行。那就是长度问题 导致分隔符切错了。
把源文件emp.txt没数据的地方 输入两个空格 作为分隔就解决了
JVM报错
在CSDN解决
Hive命令调用MR任务报错
将 hive 设置成本地模式来执行任务试试,命令如下
1 set hive.exec.mode.local.auto=true;
问题解决,但是只有一次性,hive退出就不行了,把他写到配置文件中
1 2 3 4 <property > <name > hive.exec.mode.local.auto</name > <value > true</value > </property >
问题永久解决
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的内容主要是Join语句和排序以及分区方面的一小部分内容,join语句和排序比较简单的也容易掌握,今天建表切割方面的原理方面的知识出现了缺陷,解决BUG,补充了知识点。今天的重点和难点在分区,分区能让效率提高很多,还是很重要的,能避免全局扫描,导致运行速度很慢,在公司甚至运行不起来,效率太低了。内容比较多,这部分的原理,只是一知半解,明天再好好回顾一下分区方面的内容。
7.31 函数
1.头:日期、所学内容出处
https://www.bilibili.com/video/BV1WY4y1H7d3?p=28&share_source=copy_web
2.标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 P 67067 -尚硅谷-Hive-DML 函数 查询系统函数P 68068 -尚硅谷-Hive-DML 函数 NVLP 69069 -尚硅谷-Hive-DML 函数 CASE WHEN THEN ELSE END P 70070 -尚硅谷-Hive-课程回顾P 71071 -尚硅谷-Hive-DML 函数 拼接字符串 函数说明P 72072 -尚硅谷-Hive-DML 函数 拼接字符串 函数使用P 73073 -尚硅谷-Hive-DML 函数 ExplodeP 74074 -尚硅谷-Hive-DML 函数 行转列&列转行说明P 75075 -尚硅谷-Hive-DML 函数 窗口函数 初体验P 76076 -尚硅谷-Hive-DML 函数 窗口函数 需求二P 77077 -尚硅谷-Hive-DML 函数 窗口函数 需求三P 78078 -尚硅谷-Hive-DML 函数 窗口函数 排序值相同时说明P 79079 -尚硅谷-Hive-DML 函数 窗口函数 需求四P 80080 -尚硅谷-Hive-DML 函数 窗口函数 需求五P 81081 -尚硅谷-Hive-DML 函数 窗口函数 RankP 82082 -尚硅谷-Hive-DML 函数 其他常用函数 日期函数P 83083 -尚硅谷-Hive-DML 函数 其他常用函数 数据取整函数P 84084 -尚硅谷-Hive-DML 函数 其他常用函数 字符串相关函数P 85085 -尚硅谷-Hive-DML 函数 其他常用函数 集合函数
3.所学内容概述
查询系统函数
各种系统函数
行转列 列转行
窗口函数
4.根据概述分章节描述
系统内置函数 Hive中系统自带的函数有很多 有条命令相当于API
1 2 3 show funcations; //查看系统自带的函数 desc function uppper;//显示自带函数的用发 可以翻译中文 desc function extended lower; //详细显示用法 这个好用些
常用内置函数
空字符串赋值
NVL:给值为 NULL 的数据赋值,它的格式是 NVL( value,default_value)。它的功能是如果 value 为 NULL,则 NVL 函数返回 default_value 的值,否则返回 value 的值。第二个参数可以不填,这样value如果是NULL,返回值也是NULL。
1 select comm,nvl(comm, -1) from emp; //如果comm为NULL -1代替
行转列
大白话其实就是一列转换为多列
用的到三个函数变形
1 2 3 CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串; CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数是合并参数间的分隔符。 COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生 Array 类型字段。
实例代码不太好懂 都标上注解
1 2 3 4 5 6 SELECT t1.c_b, CONCAT_WS("|",collect_set(t1.name)) --名字去重 并用|分割 FROM (SELECT NAME, --用c_b结果 CONCAT_WS(',',constellation,blood_type) c_b --合并两条数据并用,隔开 别名c_b FROM person_info )t1 --别名t1 GROUP BY t1.c_b --按照t1的c_b查询结果分组
列转行
一行转多行
1 2 3 EXPLODE(col):将 hive 一列中复杂的 Array 或者 Map 结构拆分成多行。 LATERAL VIEW 用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
案例用法
1 2 3 4 5 6 7 8 SELECT movie, category_name FROM movie_info lateral VIEW --使用函数 explode(split(category,",")) movie_info_tmp --别名 AS category_name; --作为category_name 可给上面返回查询
窗口函数
一般情况窗口函数都会搭配over使用 以四个案例来大致了解窗口函数
1 OVER ()
查询在 2017 年 4 月份购买过的顾客及总人数
1 2 3 4 select name,count(*) over () from business where substring(orderdate,1,7) = '2017-04' --筛选orderdate这一列前1-7的字符串为2017-04的 group by name; --按照name分组
查询顾客的购买明细及月购买总额
1 2 3 select name,orderdate,cost,sum(cost) --分区内cost的和 over(partition by month(orderdate)) --按照orderdate月份分区 from business;
查看顾客上次的购买时间或者下次购买时间
1 2 3 select name,orderdate,cost, lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1 --上次购买时间 lag第三个参数是如果 为null 改成1900 01 01 from business;
Rank 案例直观的感受三者的区别
1 2 3 RANK () DENSE_RANK () ROW_NUMBER ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 rank 宋宋 英语 84 1 大海 英语 84 1 婷婷 英语 78 3 孙悟空 英语 68 4 dense_rank 宋宋 英语 84 1 大海 英语 84 1 婷婷 英语 78 2 孙悟空 英语 68 3 row_ Number宋宋 英语 84 1 大海 英语 84 2 婷婷 英语 78 3 孙悟空 英语 68 4
6.扩展学习部分
Hive常用的日期 字符串 集合的方法 以及案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 常用日期函数 unix_timestamp:返回当前或指定时间的时间戳 select unix_timestamp(); select unix_timestamp("2020-10-28",'yyyy-MM-dd'); from_unixtime:将时间戳转为日期格式 select from_unixtime(1603843200); current_date:当前日期 select current_date; current_timestamp:当前的日期加时间 select current_timestamp; to_date:抽取日期部分 select to_date('2020-10-28 12:12:12'); year:获取年 select year('2020-10-28 12:12:12'); month:获取月 select month('2020-10-28 12:12:12'); day:获取日 select day('2020-10-28 12:12:12'); hour:获取时 select hour('2020-10-28 12:12:12'); minute:获取分 select minute('2020-10-28 12:12:12'); second:获取秒 select second('2020-10-28 12:12:12'); weekofyear:当前时间是一年中的第几周 select weekofyear('2020-10-28 12:12:12'); dayofmonth:当前时间是一个月中的第几天 select dayofmonth('2020-10-28 12:12:12'); months_between: 两个日期间的月份 select months_between('2020-04-01','2020-10-28'); add_months:日期加减月 select add_months('2020-10-28',-3); datediff:两个日期相差的天数 select datediff('2020-11-04','2020-10-28'); date_add:日期加天数 select date_add('2020-10-28',4); date_sub:日期减天数 select date_sub('2020-10-28',-4); last_day:日期的当月的最后一天 select last_day('2020-02-30'); date_format(): 格式化日期 select date_format('2020-10-28 12:12:12','yyyy/MM/dd HH:mm:ss'); 常用取整函数 round: 四舍五入 select round(3.14); select round(3.54); ceil: 向上取整 select ceil(3.14); select ceil(3.54); floor: 向下取整 select floor(3.14); select floor(3.54); 常用字符串操作函数 upper: 转大写 select upper('low'); lower: 转小写 select lower('low'); length: 长度 select length("atguigu"); trim: 前后去空格 select trim(" atguigu "); lpad: 向左补齐,到指定长度 select lpad('atguigu',9,'g'); rpad: 向右补齐,到指定长度 select rpad('atguigu',9,'g'); regexp_replace:使用正则表达式匹配目标字符串,匹配成功后替换! SELECT regexp_replace('2020/10/25', '/', '-'); 集合操作 size: 集合中元素的个数 select size(friends) from test3; map_keys: 返回map中的key select map_keys(children) from test3; map_values: 返回map中的value select map_values(children) from test3; array_contains: 判断array中是否包含某个元素 select array_contains(friends,'bingbing') from test3; sort_array: 将array中的元素排序 select sort_array(friends) from test3; grouping_set:多维分析
7.总结
重点是哪些知识比较重要,难点是你在学习过程中觉得比较繁琐,掌握起来有一点
今天的学习任务是Hive的函数部分,其实就是了解Hive中对数据处理的各种方式,有一些处理方式,有点像Java中的几个函数,改了名字。实际作用是差不多的,合理使用函数,对数据处理的效率能提高不少。这些函数对数据的筛选和过滤,利用好分区和分组加排序,能很灵活的对数据处理。今天难度简单吧,基本全部掌握了,列转行这里有些函数没有去尝试过,也没出BUG,学习状态也不错。